Introduction
When building real-time applications that have a rich UI, we often need to make lots of concurrent requests to a database to populate parts of the page. In order to not expose database credentials in the web browser, the common practice is to put a web server between the database and the client.
This added complexity is necessary for some applications, but it can be overkill when building single page applications, proof of concepts, and demos where users need to iterate quickly. Instead developers can consider adopting a "client only" architecture, where the browser queries the database directly. In this post, we highlight some of the key database considerations of adopting a "client only" architecture.
Single page applications that dynamically update content on a single webpage, without full page reloads by handling all rendering and logic on the client side, are particularly applicable to this approach with the aim of delivering a seamless user experience.
We'll show how this can be implemented with ClickHouse, while ensuring the database remains secure and isn't overwhelmed with requests. This requires us to exploit several simple but powerful features and reuse a few configuration recipes that can be used to add analytics safely to an existing application in minutes with just a little Javascript.
We use this very same "client only" approach successfully for many of our public demos, including ClickPy, CryptoHouse, and adsb.exposed which are also single page applications. However, we also appreciate that some users need an additional level of security and wish to minimize their attack surface by adding an API layer. For this, ClickHouse Cloud provides Query Endpoints.
Background
Traditionally, web applications followed a traditional client-server architecture. In this model, the frontend communicated with a backend server through APIs, and the server handled database interactions.

This setup required developers to build and maintain complex backend infrastructure, adding layers of complexity to the development process and slowing down iteration cycles. This architecture was primarily prominent due to security concerns about providing direct database access from the front end and exposing a database to the public internet, thus necessitating secure API communication. This architecture has inherent complexities, however, and poses additional scalability challenges - backend servers need careful management and manual tuning to handle growth effectively. In summary, this made developing and maintaining web apps resource-intensive and less efficient.
In recent years, we've seen increased adoption of allowing database access directly from the client-side code in the browser. This approach to building web applications was popularized by Firebase, particularly through its Firebase Realtime Database, which introduced the concept of browser-based access with security rules that could be managed via tokens, including anonymous authentication tokens.
Firebase's popularity in the frontend-driven development community established this practice, which other services like Supabase have adopted and adapted for PostgreSQL-based databases. This has simplified development and enabled faster iteration by reducing the need for complex backend infrastructure and simplified scalability by delegating it to the database.
These database services are, however, typically optimized for transactional workloads - perfect for handling your application state, but less suited to provide analytics and rich visuals over large datasets. Fortunately, ClickHouse can be deployed in this architecture with a little configuration.
The following recommendations are for users looking to adopt a client-only architecture with ClickHouse. For users looking for a simpler experience, we recommend Query Endpoints in ClickHouse Cloud which abstract much of the complexity away and allow ClickHouse’s fast analytical query capabilities to be consumed over configurable REST endpoints.
Using ClickHouse for single page applications
ClickHouse has several key features that enable it to be used in a client-only architecture:
- HTTP interface & REST API - making it trivial to query ClickHouse with SQL from Javascript. By default, ClickHouse listens on port 8123 or 8443 (if SSL), with the latter exposed in ClickHouse Cloud. This interface includes support for HTTP compression and sessions.
- Output formats - support for over 70 output data formats, including 20 sub formats for JSON allowing easy parsing with Javascript.
- Query parameters - allowing queries to be templated and remain robust to SQL injections.
- Role Based Access Control - allowing administrators to limit access to specific tables and rows.
- Restrictions on query complexity - restrict users to be read only as well as limit the query complexity and resources available.
- Quotas - to limit the number of queries from any specific client, thus preventing rogue or malicious clients overwhelming the database.
For example, below, we query our ClickPy instance for the most downloaded Python packages in the last 30 days. Note the use of a play user and FORMAT JSONEachRow (default TabSeparated) parameter requesting the data be returned as pretty-printed JSON.
echo 'SELECT project, sum(count) as c FROM pypi.pypi_downloads GROUP BY project ORDER BY c DESC LIMIT 3 FORMAT JSONEachRow' | curl -u play: 'https://clickpy-clickhouse.clickhouse.com' --data-binary @-
{"project":"boto3","c":"27234697969"}
{"project":"urllib3","c":"17015345004"}
{"project":"botocore","c":"15812406924"}
While these features provide the necessary building blocks to ensure ClickHouse can be queried from the browser, they must be carefully configured and applied - especially when exposing an instance to the public internet.
We focus on read requests only when describing these best practices. These are typically the only appropriate requests to allow when developing client-only public-facing applications. We also assume all clients (actual users) are issuing queries with the same username. However, these principles can easily be expanded to multiple ClickHouse users.
HTTPS only
For public-facing applications, the user credentials used for most queries will be available in the browser and visible to any developer who inspects the network requests. Although these credentials should not be considered sensitive, applications may allow users to modify the username and password used for the request. These credentials should be protected and thus only transmitted over a secure connection. For how to configure TLS for open-source ClickHouse and expose an HTTPS interface, see here.
For example, imagine an application similar to the ClickHouse play environment where the user can modify the username and password if they create an account. Potentially this user might have elevated permissions or higher quotas.
ClickHouse Cloud only exposes a secure HTTP interface on port 8443.
Allowing cross-origin requests
To ensure browsers can run queries against ClickHouse from apps hosted on different domains, cross origin requests should be enabled in ClickHouse. In ClickHouse Cloud this is enabled by default:
curl -X OPTIONS -I https://clickpy-clickhouse.clickhouse.com -H "Origin: localhost:3000"
HTTP/1.1 204 No Content
Date: Fri, 27 Sep 2024 13:30:36 GMT
Connection: Close
Access-Control-Allow-Origin: *
Access-Control-Allow-Headers: origin, x-requested-with, x-clickhouse-format, x-clickhouse-user, x-clickhouse-key, Authorization
Access-Control-Allow-Methods: POST, GET, OPTIONS
Access-Control-Max-Age: 86400
OSS users can enable this by modifying the appropriate settings in config.xml. Configure this according to normal best practices, considering whether you want to restrict access to just your application domain or allow users to use your clickhouse data in broader contexts.
<!-- It is off by default. Next headers are obligate for CORS.-->
<http_options_response>
<header>
<name>Access-Control-Allow-Origin</name>
<value>*</value>
</header>
<header>
<name>Access-Control-Allow-Headers</name>
<value>origin, x-requested-with</value>
</header>
<header>
<name>Access-Control-Allow-Methods</name>
<value>POST, GET, OPTIONS</value>
</header>
<header>
<name>Access-Control-Max-Age</name>
<value>86400</value>
</header>
</http_options_response>
Usually JSON formats
With native support in Javascript, JSON is the preferred data exchange format for web development. ClickHouse supports over 20 JSON formats, each with its own subtle differences. In general, the JSON format provides the most structured and complete response with information on the columns and their types, the data and query statistics. We can test this with the fetch API:
const credentials = btoa('play:');
const response = await fetch('https://clickpy-clickhouse.clickhouse.com', {
method: 'POST',
body: 'SELECT project, sum(count) as c FROM pypi.pypi_downloads GROUP BY project ORDER BY c DESC LIMIT 3 FORMAT JSON',
headers: {
'Authorization': `Basic ${credentials}`,
'Content-Type': 'application/x-www-form-urlencoded'
}
});
const data = await response.json();
console.log(JSON.stringify(data, null, 2));
{
"meta": [
{
"name": "project",
"type": "String"
},
{
"name": "c",
"type": "Int64"
}
],
"data": [
{
"project": "boto3",
"c": "27234697969"
},
{
"project": "urllib3",
"c": "17015345004"
},
{
"project": "botocore",
"c": "15812406924"
}
],
"rows": 3,
"rows_before_limit_at_least": 695858,
"statistics": {
"elapsed": 0.057031395,
"rows_read": 1046002,
"bytes_read": 32165070
}
}
There are variants of this format, such as JSONObjectEachRow and JSONColumnsWithMetadata, that users find easier to parse for their use case. These formats all return the response within an outer JSON object and thus require the entire payload to be parsed and loaded into memory. For smaller responses, this is rarely a concern. For larger formats, users may wish to consider a format from the EachRow family, which is more easily parsed with the Streams API as shown in this simple example. These formats, such as JSONEachRow, JSONCompactEachRow, and JSONEachRowWithProgress, are not strictly well-formatted JSON - more representing NDJSON - more can be read.
Other formats are variants of TSV and CSV, allowing data to be easily downloaded. For users requiring high performance on large data volumes, e.g., rendering in web assembly libraries such as Perspective, ClickHouse additionally supports the Arrow and ArrowStream formats. For an example, see here.
Query statistics, sessions & error handling
The ClickHouse HTTP interface allows query statistics to be sent as response headers describing the progress of the query. These can be tricky to read, and generally, we recommend using the format JSONEachRowWithProgress to obtain statistics on the progress of running queries.
Users can also read an X-ClickHouse-Summary header, which summarizes the read rows, bytes, and execution time.
echo 'SELECT project, sum(count) as c FROM pypi.pypi_downloads GROUP BY project ORDER BY c DESC LIMIT 3 FORMAT JSONEachRow' | curl -i -u play: 'https://clickpy-clickhouse.clickhouse.com' --data-binary @-
HTTP/1.1 200 OK
Date: Fri, 27 Sep 2024 15:02:22 GMT
Connection: Keep-Alive
Content-Type: application/x-ndjson; charset=UTF-8
X-ClickHouse-Server-Display-Name: clickhouse-cloud
Transfer-Encoding: chunked
X-ClickHouse-Query-Id: f05b0e25-8b9d-4d28-ad79-fe31e34acfbf
X-ClickHouse-Format: JSONEachRow
X-ClickHouse-Timezone: UTC
Keep-Alive: timeout=10
X-ClickHouse-Summary: {"read_rows":"1046002","read_bytes":"32165070","written_rows":"0","written_bytes":"0","total_rows_to_read":"1046002","result_rows":"0","result_bytes":"0","elapsed_ns":"45896728"}
{"project":"boto3","c":"27234697969"}
{"project":"urllib3","c":"17015345004"}
{"project":"botocore","c":"15812406924"}
Note that unless the query parameter wait_end_of_query=1 is included in the request, the summary statistics may not represent the entire query execution. Without this setting the response will be streamed with the header value returned prior to the query completes. Including this setting causes the response to only be returned once the query completes, with accurate statistics. Be aware this causes the response to buffer on the suffer (possibly consuming significant memory) and will delay the response being served, and is therefore inappropriate in cases of large numbers of rows being read.
echo 'SELECT project, sum(count) as c FROM pypi.pypi_downloads GROUP BY project ORDER BY c DESC LIMIT 3 FORMAT JSONEachRow' | curl -i -u play: 'https://clickpy-clickhouse.clickhouse.com' --data-binary @-
HTTP/1.1 200 OK
Date: Fri, 27 Sep 2024 15:02:22 GMT
Connection: Keep-Alive
Content-Type: application/x-ndjson; charset=UTF-8
X-ClickHouse-Server-Display-Name: clickhouse-cloud
Transfer-Encoding: chunked
X-ClickHouse-Query-Id: f05b0e25-8b9d-4d28-ad79-fe31e34acfbf
X-ClickHouse-Format: JSONEachRow
X-ClickHouse-Timezone: UTC
Keep-Alive: timeout=10
X-ClickHouse-Summary: {"read_rows":"1046002","read_bytes":"32165070","written_rows":"0","written_bytes":"0","total_rows_to_read":"1046002","result_rows":"0","result_bytes":"0","elapsed_ns":"45896728"}
{"project":"boto3","c":"27234697969"}
{"project":"urllib3","c":"17015345004"}
{"project":"botocore","c":"15812406924"}
We also suggest users familiarize themselves with error handling. On receiving a syntactically correct query, ClickHouse will send results when possible (unless wait_end_of_query=1) with a response code 200. If, later in the query execution (potentially hours later), an error occurs, the stream may be terminated with the payload containing the error - consider this example. This is left to the user to process.
This can only be partially mitigated with wait_end_of_query=1. If processing responses manually, we, therefore, always recommend processing the response and ensuring it's correct.
Just use the client library!
For anything except the most simple use cases we recommend users just the official web client. This client supports most of the common request formats as well as ensuring the correct handling of sessions, compression, errors and strategies for long running queries. Streaming selects are exposed in a simple interface which has been optimized, with the additional benefit of providing a typed interface.
import { createClient } from '@clickhouse/client-web';
void (async () => {
const client = createClient( {
url: 'https://clickpy-clickhouse.clickhouse.com',
username: 'play'
}
);
const rows = await client.query({
query:
'SELECT project, sum(count) as c FROM pypi.pypi_downloads GROUP BY project ORDER BY c DESC LIMIT 3',
format: 'JSONEachRow',
});
const result = await rows.json();
result.map(row => console.log(row));
await client.close();
})();
Use query parameters
Query parameters allow queries to be templated, avoiding the need to manipulate SQL statements as strings, e.g. when filter values change in an interface. Users should always prefer query parameters over string manipulation, with ClickHouse ensuring the former is robust to SQL injection attacks. The web client provides a clean interface to exploit this functionality.
import { createClient } from '@clickhouse/client-web';
void (async () => {
const client = createClient({
url: 'https://clickpy-clickhouse.clickhouse.com',
username: 'play',
});
const rows = await client.query({
query:
'SELECT sum(count) as c FROM pypi.pypi_downloads WHERE project = {project:String}',
format: 'JSONEachRow',
query_params: {
project: 'clickhouse-connect',
}
});
const result = await rows.json();
result.map(row => console.log(row));
await client.close();
})();
Principle of least privilege
Always adopt a principle of least privilege when granting users permission to access tables - ClickHouse obeys this principle with newly created users having no permissions (unless assigned a default role).
Tip: If creating a user that will be used for client-only requests, creating a password generally serves no purpose since credentials will be visible to users of an application. To create a user with no password:
-- oss
CREATE USER play IDENTIFIED WITH no_password;
-- clickhouse cloud
CREATE USER play IDENTIFIED WITH double_sha1_hash BY 'BE1BDEC0AA74B4DCB079943E70528096CCA985F8';
Generally we recommend creating a role, in case further users are required (for now we assume all clients use the same user), and granting this the following permissions.
Initially, establish the tables and columns the web user should be able to access - granting SELECT accordingly. For example, the following allows any user with the play_role to read all tables (and columns) in the pypi database. Users with this role are limited to reading the event_type and actor_login columns (this must be done explicitly i.e. * is not permitted) for the events table in the github database.
Note we also grant the role to our earlier play user.
-- create the role
CREATE ROLE play_role;
-- limit read on the columns event_type, actor_login for the github.events table
GRANT SELECT(event_type, actor_login ) ON github.events TO play_role;
-- allow select on all tables in the pypi database
GRANT SELECT ON pypi.* TO play_role;
-- grant the role to the user
GRANT play_role TO play;
Row-based policies can also be applied, allowing users to see only specific rows for a given table. See here for further details.
Read-only & common limits
The above creates a limited user with SELECT permissions. We can apply further constraints by creating a settings profile and applying this to the role.
This profile should further limit the user to read-only operations, setting read_only=1 for the user's role. This limits to read-only queries while also preventing queries that modify session context or change settings. While this imposes read only restrictions to the user it does not limit their abilities to execute complex queries. For this, we can add restrictions on query complexity to the profile.
These allow fine control over all aspects of the execution. The number of settings here is extensive, but at a minimum, we recommend the following:
max_execution_time- max execution time for a query.max_rows_to_readandmax_bytes_to_read- max rows and bytes to read per query.max_result_rowsandmax_result_bytes- maximum rows and bytes to return in a response.max_memory_usage- max memory usage allowed for a query.max_bytes_before_external_group_by- the memory allowed for a GROUP BY before overflowing to disk.
As an example, consider the following settings profile used for the play user in play.clickhouse.com with sensible values.
CREATE SETTINGS PROFILE `play` SETTINGS readonly = 1, max_execution_time = 60, max_rows_to_read = 10000000000, max_result_rows = 1000, max_bytes_to_read = 1000000000000, max_result_bytes = 10000000, max_network_bandwidth = 25000000, max_memory_usage = 20000000000, max_bytes_before_external_group_by = 10000000000, enable_http_compression = true
--assign settings profile to the role
ALTER USER play SETTINGS PROFILE play_role
Importantly, all of these settings are per query. We need quotas (see below) to limit the number of queries.
By default, if a query exceeds these limits, an error is thrown. In cases where the application has a restricted set of queries this behavior is acceptable, with the principle intention to stop abusive users. However, in some cases, you might want to allow users to receive a partial response on hitting a limit, e.g., rows read. This is the case, for example, in CryptoHouse, where users can run an arbitrary select, and we return the current results.
To achieve this, set the overflow mode to break for the settings being restricted in the profile. For example, the setting result_overflow_mode = 'break' will interrupt execution when the limit set by max_result_rows is reached.
Note the amount of returned rows will be greater than
max_result_rowsand will be a multiple ofmax_block_sizeandmax_threads, as execution is interrupted at a block level.
Typically, we find the setting read_overflow_mode=break also to be useful with this causing a break in execution if excessive rows are read with current results returned. Users can detect this interruption (and show a warning) by checking the read_rows in the summary statistics vs the known limit.
Expose settings if needed
Users configured to be read-only (via readonly=1) cannot change settings at query time. While this is typically desirable, there are use cases where it may make sense. For example, the max_execution_time needs to be modifable by Grafana for read-only users. Additionally, you may wish users to be able to optionally use response compression depending on the expected result set size (this requires enable_http_compression=1 ).
Rather than using readonly=2, which allows the user to change all settings, we recommend applying constraints to the settings. These allow users to change designated settings within specified constraints.
These constraints allow an acceptable range to be specified for a numeric setting via a min and max. Settings that accept an enum of values can be defined as changeable via the changeable_in_readonly constraints. These allow a specified setting to be adjusted within the defined min/max range, even when readonly is set to 1. Otherwise, settings cannot be changed when readonly=1.
The changeable_in_readonly is only available if settings_constraints_replace_previous is enabled in the clickhouse.xml configuration.
<access_control_improvements>
<settings_constraints_replace_previous>true</settings_constraints_replace_previous>
</access_control_improvements>
As an example, consider the following profile:
CREATE SETTINGS PROFILE `play` SETTINGS readonly = 1, max_execution_time = 2, enable_http_compression = false
This prevents the use of HTTP compression for the users with this settings profile and limits execution time to 2s. The following queries, therefore all fail:
echo "SELECT sleep(3)" | curl -s -u play: 'https://clickpy-clickhouse.clickhouse.com
' --data-binary @-
Code: 159. DB::Exception: Timeout exceeded: elapsed 2.002346261 seconds, maximum: 2. (TIMEOUT_EXCEEDED) (version 24.6.1.4501 (official build))
echo "SELECT sleep(1) SETTINGS enable_http_compression=1" | curl -u play: 'https://clickpy-clickhouse.clickhouse.com?compress=true' --data-binary @- -H 'Accept-Encoding: gzip' --output -
Code: 164. DB::Exception: Cannot modify 'enable_http_compression' setting in readonly mode. (READONLY) (version 24.6.1.4501 (official build))
We can modify our settings profile to allow these settings to be modified using constraints.
ALTER SETTINGS PROFILE `play` SETTINGS readonly = 1, max_execution_time = 10 CHANGEABLE_IN_READONLY min=1 max=60, enable_http_compression = false CHANGEABLE_IN_READONLY
The earlier queries can now be configured to execute:
echo "SELECT sleep(3) SETTINGS max_execution_time=4" | curl -s -u play_v2: 'https://k5u1q15mc4.us-central1.gcp.clickhouse.cloud' --data-binary @-
0
echo "SELECT sleep(1) SETTINGS enable_http_compression=1" | curl -u play_v2: 'https://k5u1q15mc4.us-central1.gcp.clickhouse.cloud?compress=true' --data-binary @- -H 'Accept-Encoding: gzip' --output -
}''ߨ')CN''
')'2'
Apply Quotas
All of our earlier settings only restrict a single query and do not apply any limitations to overall query throughput. A malicious user, with restrictions limiting individual queries, could still run thousands of concurrent queries, consuming all available resources.
To limit the number of queries for a specific username, we can create a quota and apply it to an assigned role. A quota restricts the number of queries per unit time. Importantly, many actual users or clients query with the same username. We want our quota to apply to each of these clients, not just the username - or a single malicious client could exhaust limits for everyone!
For this, we key the quota off the IP address. This causes limits to be tracked per IP. As an example, we create a quota play below, allowing up to 2 queries per minute and assign this to the play_role.
CREATE QUOTA play KEYED BY ip_address FOR INTERVAL 1 minute MAX queries = 2 TO play_role
Querying without play user, we can exceed these quota limits easily:
echo "SELECT sum(number) FROM numbers(1000)" | curl -u play_v2: 'https://k5u1q15mc4.us-central1.gcp.clickhouse.cloud' --data-binary @-
Code: 201. DB::Exception: Quota for user `play_v2` for 60s has been exceeded: queries = 2/1. Interval will end at 2024-09-27 16:52:00. Name of quota template: `play_v2`. (QUOTA_EXCEEDED) (version 24.6.1.4501 (official build))
In ClickHouse Cloud, quotas are per replica. Ensure you consider this when setting values.
Multiple users for different roles
When developing functionality, it's not uncommon to want different limits for different functional parts of the app. For example, the username used to execute queries might be limited to the number of queries it can run per hour. Conversely, you may have a component that needs to be regularly updated to show a statistic. This data may be obtained from a materialized view and need to be updated every second—much faster than the standard user.
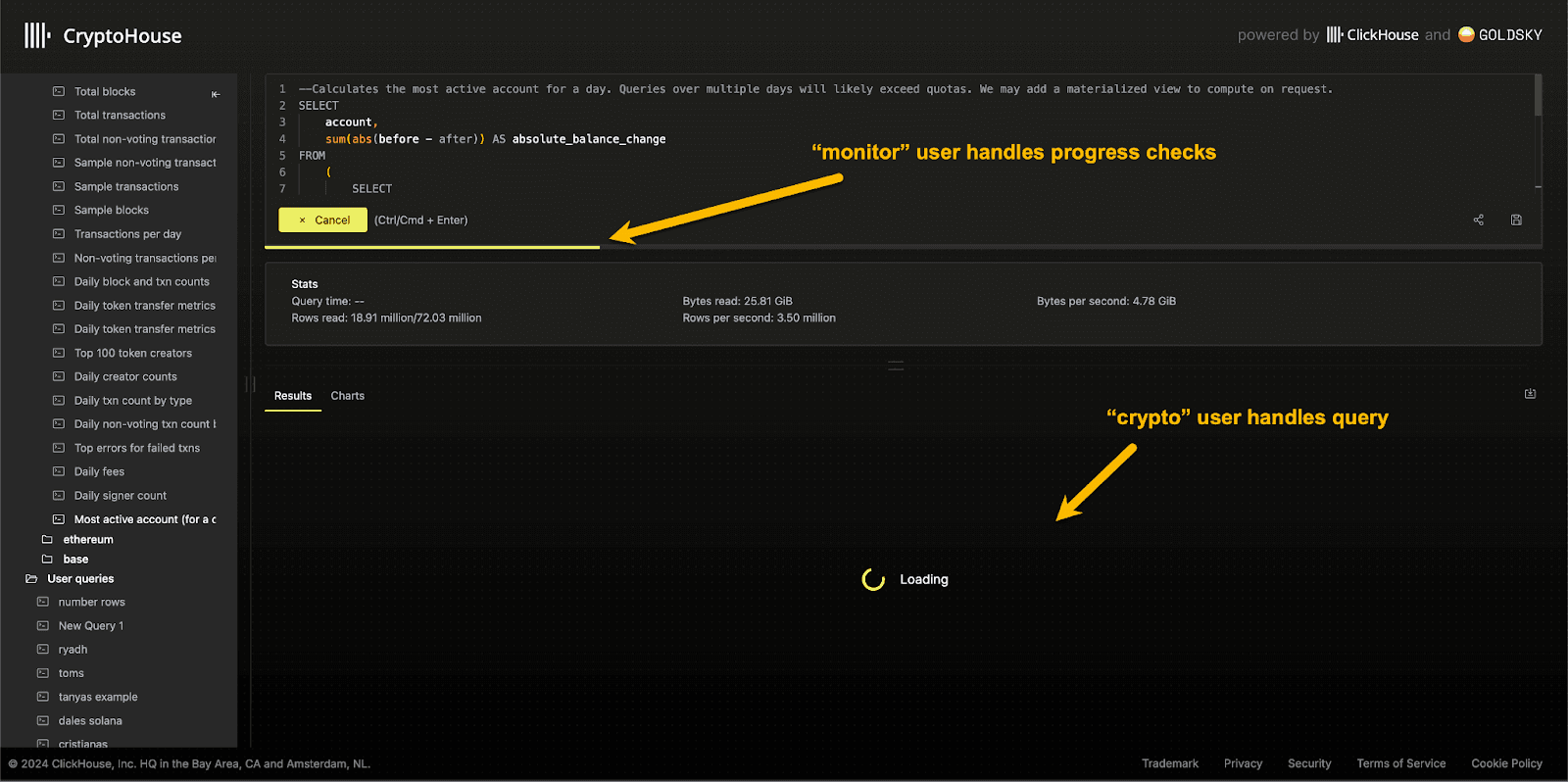
To achieve this, we typically recommend creating different users with different roles and quotas as required. This use case is the case in CryptoHouse, where the user used to run queries crypto is limited to 120 queries per hour. Conversely, the user used to fetch the progress of a query as it executes uses a monitor user with much higher quota limits but is conversely restricted to a specific table.
Use Materialized Views
We recommend developers ensure frequently executed queries are performed against Materialized Views. In its simplest form, a Materialized view in ClickHouse is simply a query that triggers when an insert is made to a table. Key to this is the idea that Materialized Views don't hold any data themselves. They simply execute a query on the inserted rows and send the results to another "target table" for storage.
Importantly, the query that runs can aggregate the rows into a smaller result set, allowing queries to run faster on the target table. This approach effectively moves work from query time to insert time and avoids queries hitting complexity limits while minimizing the resources required to run a query and ensuring the UI is as responsive as possible.
We employ this technique in our popular ClickPy demo, which allows users to perform analytics on Python packages. Example views and details on the implementation can be found here.
Exploiting compression
ClickHouse's HTTP endpoint supports both request and response compression. For the text-based formats described above, we recommend using HTTP response compression. Since read requests are typically small, users typically only need response compression when developing client-only applications. We recommend only enabling compression when streaming large responses where the network is the bottleneck. Compression may slow response times with a CPU overhead incurred on the server. As always, test and measure.
Provided enable_http_compression=1 is set for the user (or set in the request), the desired compression method should be specified in the header Accept-Encoding: compression_method, with a number of options supported.
const client = createClient( {
url: 'https://clickpy-clickhouse.clickhouse.com',
username: 'play',
compression: {
response: true
}
}
);
If compression is required, we recommend the ClickHouse JS web client, which supports response compression with gzip, as shown above, and automatically sets the required header and settings.
Predefined HTTP Interfaces
Open-source users can abstract SQL away from the client using pre-defined HTTP interfaces. This feature allows ClickHouse to expose an endpoint to which parameters are provided. These are, in turn, injected into a predefined SQL query, with the response returned to the user. For simple business applications, this can simplify the client code which just communicates with a limited REST API. The same principles described above can be applied to the invoking user to enforce access restrictions and quotas.
Query Endpoints for ClickHouse Cloud
Pre-defined HTTP interfaces have their limitations, not least implementing changes or adding endpoints requires modifying the clickhouse.xml configuration.
Some users may also not feel comfortable exposing their ClickHouse HTTP interface. Query Endpoints help address these concerns by limiting the queries that can be executed, thus reducing the attack surface.
ClickHouse Cloud exposes a similar but more advanced feature in Query Endpoints using a token-based authentication mechanism. In addition to templating queries, users can assign roles to the endpoints (through which settings constraints and quotas can be applied) and configure CORs per endpoint. These endpoints can be easily added or modified at any time from the ClicKHouse Cloud's unified console.
API endpoints do more than simplify an interface - they add separation of concerns. As well as making it simpler to update an application query, without having to modify or redeploy the code, this allows teams to easily expose analytics without needing to write SQL or interact directly with a ClickHouse database owned by different teams. All of the best practices we have outlined above are abstracted behind these endpoints, with developers just tasked with interacting with simple REST API endpoints.
For an example of this, we recommend this blog.
Conclusion
A client-only architecture can be ideal for small applications, demos,, and single-page applications, simplifying development and enabling faster iteration with scaling concerns offloaded to the database. This does, however, require the target database to support both an HTTP interface and the required features to make the database safe to expose clients. While Firebase and Supabase have popularized this architecture for OLTP workloads, ClickHouse has the necessary features to allow this to be adopted for real-time analytics. We have provided comprehensive recommendations for configuring ClickHouse to be used in such an architecture. For users looking for a simpler experience, Query Endpoints in ClickHouse abstract much of the complexity away and allow ClickHouse’s fast analytical query capabilities to be consumed over simple REST endpoints.


