はじめに
実世界ではデータは保存するだけではなく、同時に処理を行う必要があります。通常、この処理はアプリケーション側で行い、ClickHouse 向けの利用可能なライブラリのいずれかを使用します。しかし、パフォーマンスとデータの管理性を高めるために、重要な処理を ClickHouse に任せられるケースがあります。ClickHouse においてそのために最も強力なツールの一つが、Materialized Viewです。本記事では、Materialized Viewとは何か、そしてクエリの高速化やデータの変換・フィルタリング・ルーティングなどにどのように活用できるかを解説します。
もしMaterialized Viewについて詳しく学びたい場合は、こちらで無料オンデマンドのトレーニングコースをご覧いただけます。
Materialized Viewとは
Materialized Viewは、データがソーステーブルに挿入されるタイミングで、そのデータに対する SELECT クエリ結果をターゲットテーブルに保存する特別なトリガーです:
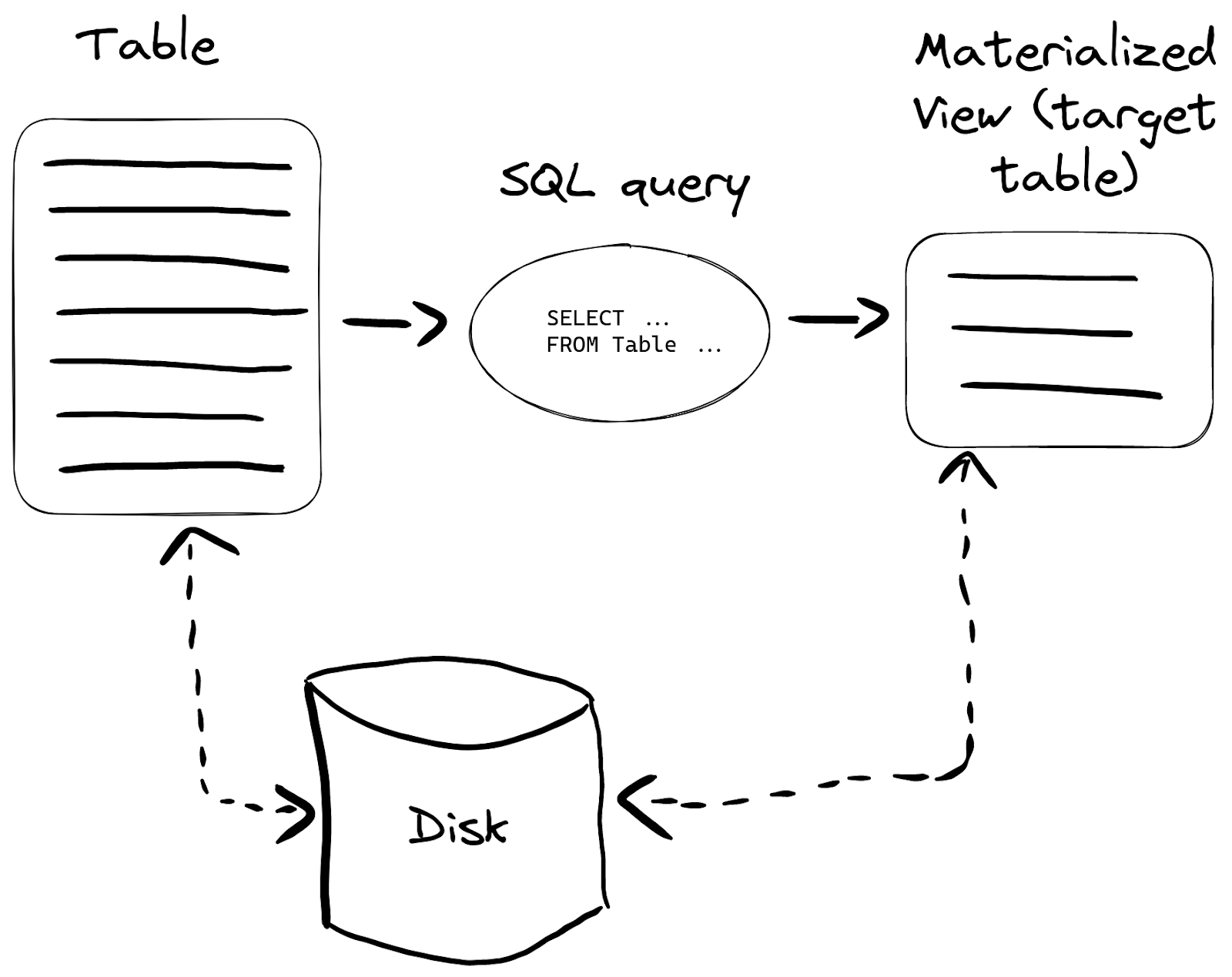
さまざまなケースで有効ですが、一番よくある使い方としては特定のクエリをより高速にすることが挙げられます。
かんたんな例
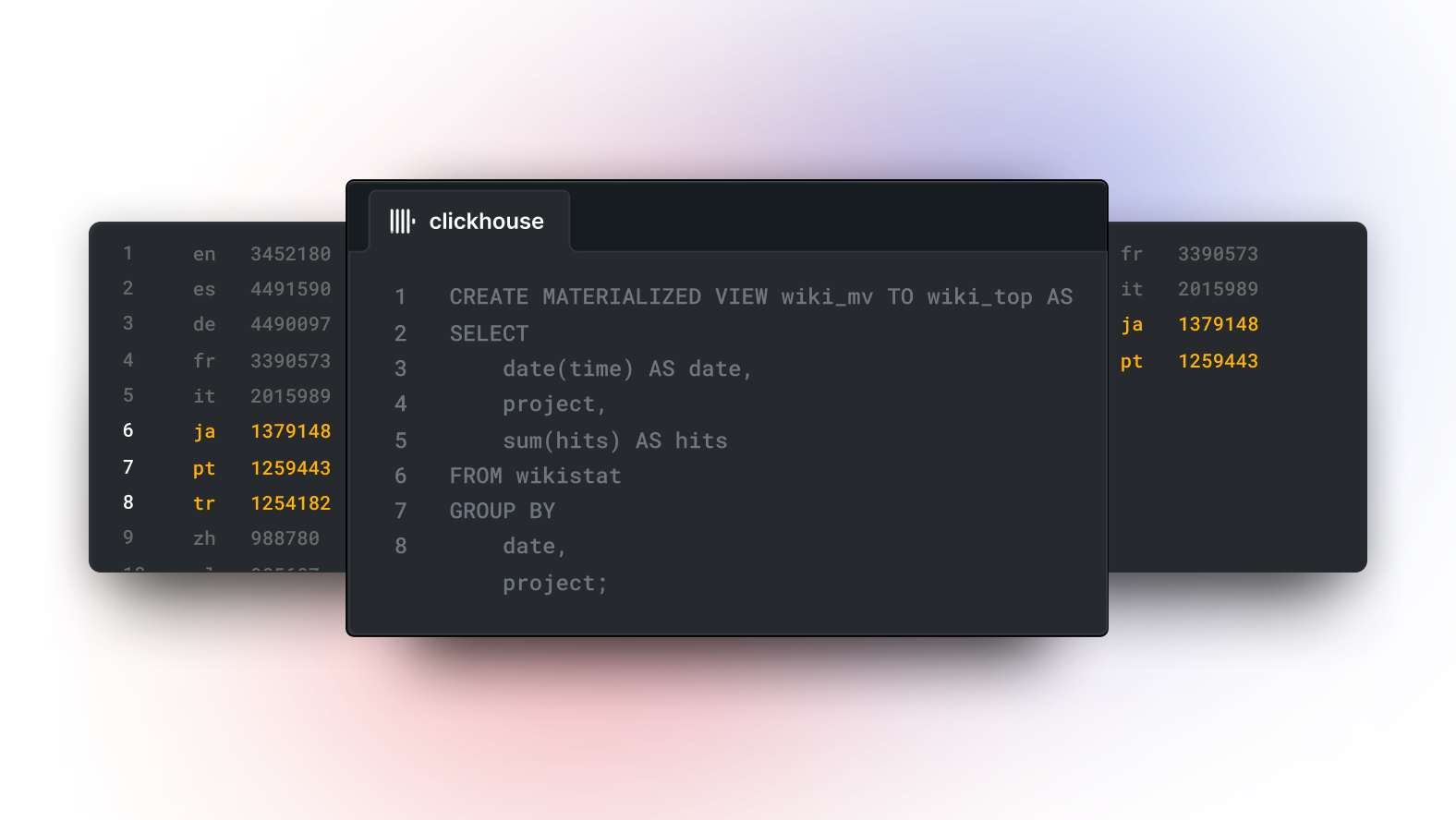
Wikistat データセットの 10 億行(1b rows)を例にとりましょう:
CREATE TABLE wikistat ( `time` DateTime CODEC(Delta(4), ZSTD(1)), `project` LowCardinality(String), `subproject` LowCardinality(String), `path` String, `hits` UInt64 ) ENGINE = MergeTree ORDER BY (path, time); Ok. INSERT INTO wikistat SELECT * FROM s3('https://ClickHouse-public-datasets.s3.amazonaws.com/wikistat/partitioned/wikistat*.native.zst') LIMIT 1e9
たとえば、ある日付における最も人気のあるプロジェクト(hits の合計が大きい順)を頻繁にクエリするとします:
SELECT project, sum(hits) AS h FROM wikistat WHERE date(time) = '2015-05-01' GROUP BY project ORDER BY h DESC LIMIT 10
このクエリは ClickHouse Cloud の開発用サービスで約 15 秒かかります:
┌─project─┬────────h─┐ │ en │ 34521803 │ │ es │ 4491590 │ │ de │ 4490097 │ │ fr │ 3390573 │ │ it │ 2015989 │ │ ja │ 1379148 │ │ pt │ 1259443 │ │ tr │ 1254182 │ │ zh │ 988780 │ │ pl │ 985607 │ └─────────┴──────────┘ 10 rows in set. Elapsed: 14.869 sec. Processed 972.80 million rows, 10.53 GB (65.43 million rows/s., 708.05 MB/s.)
こうしたクエリが大量にあり、かつサブセカンド(1 秒未満)のパフォーマンスが必要であれば、このクエリ専用のMaterialized Viewを作成できます:
CREATE TABLE wikistat_top_projects ( `date` Date, `project` LowCardinality(String), `hits` UInt32 ) ENGINE = SummingMergeTree ORDER BY (date, project); Ok. CREATE MATERIALIZED VIEW wikistat_top_projects_mv TO wikistat_top_projects AS SELECT date(time) AS date, project, sum(hits) AS hits FROM wikistat GROUP BY date, project;
これら 2 つのクエリでは以下のようになります:
wikistat_top_projectsはMaterialized Viewの結果を保存するためのターゲットテーブルの名前wikistat_top_projects_mvはMaterialized Viewそのもの(トリガー)の名前- SummingMergeTree を使うのは、日付/プロジェクトごとに
hitsを合計したいから ASの後に続く部分がMaterialized Viewを構築するためのクエリ
Materialized Viewはいくつでも作成できますが、新しく作るたびに追加のストレージ負荷が発生するので、1 テーブルあたり 10 個未満程度にとどめるのが一般的です。
同じクエリを使って wikistat テーブルのデータをターゲットテーブルに流し込み、Materialized Viewを初期化しましょう:
INSERT INTO wikistat_top_projects SELECT date(time) AS date, project, sum(hits) AS hits FROM wikistat GROUP BY date, project
Materialized View テーブルにクエリする
wikistat_top_projects は普通のテーブルなので、ClickHouse SQL のすべての機能を使ってクエリできます:
SELECT project, sum(hits) hits FROM wikistat_top_projects WHERE date = '2015-05-01' GROUP BY project ORDER BY hits DESC LIMIT 10 ┌─project─┬─────hits─┐ │ en │ 34521803 │ │ es │ 4491590 │ │ de │ 4490097 │ │ fr │ 3390573 │ │ it │ 2015989 │ │ ja │ 1379148 │ │ pt │ 1259443 │ │ tr │ 1254182 │ │ zh │ 988780 │ │ pl │ 985607 │ └─────────┴──────────┘ 10 rows in set. Elapsed: 0.003 sec. Processed 8.19 thousand rows, 101.81 KB (2.83 million rows/s., 35.20 MB/s.)
元のクエリでは 15 秒かかった処理が、3 ミリ秒で結果を得られるようになりました。ただし SummingMergeTree は非同期で合計を管理しているため、完全な合計が計算されていない場合があります。そのため、クエリ時に GROUP BY が必要なケースもあります。
Materialized Viewの管理
Materialized Viewは SHOW TABLES クエリで一覧表示できます:
SHOW TABLES LIKE 'wikistat_top_projects_mv' ┌─name─────────────────────┐ │ wikistat_top_projects_mv │ └──────────────────────────┘
DROP TABLE でMaterialized Viewを削除できますが、これはトリガーのみを削除します:
DROP TABLE wikistat_top_projects_mv
ターゲットテーブル自体も不要な場合は別途削除しましょう:
DROP TABLE wikistat_top_projects
Materialized Viewのディスク使用量を確認する
Materialized Viewのターゲットテーブルも、他のテーブルと同様に system データベースでメタデータを確認できます。たとえばディスク上のサイズは次のように確認します:
SELECT rows, formatReadableSize(total_bytes) AS total_bytes_on_disk FROM system.tables WHERE table = 'wikistat_top_projects' ┌──rows─┬─total_bytes_on_disk─┐ │ 15336 │ 37.42 KiB │ └───────┴─────────────────────┘
Materialized Viewの更新
Materialized Viewの最も強力な機能は、ソーステーブルにデータが挿入されると、ターゲットテーブルも自動的に更新されることです:
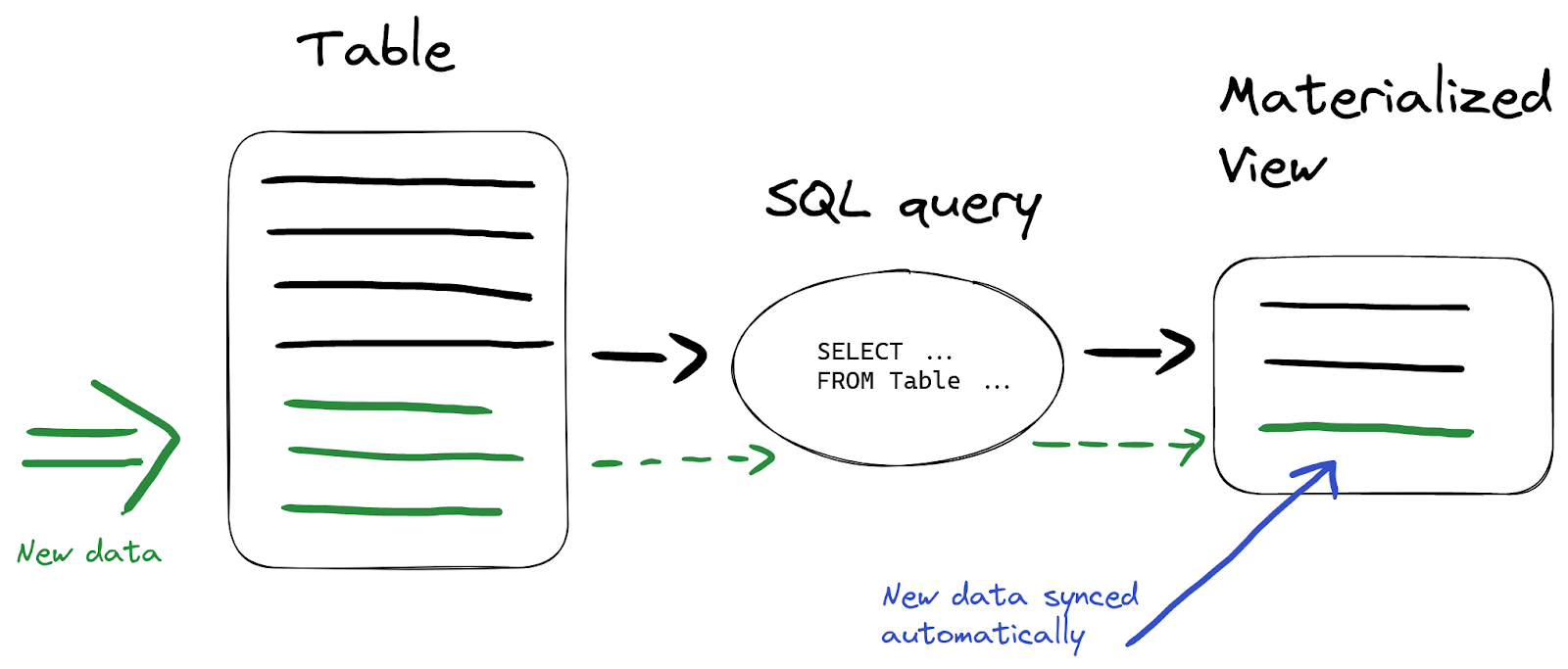
つまり、ビューのデータを手動でリフレッシュする必要はありません。たとえば wikistat テーブルに新しいデータを挿入してみます:
INSERT INTO wikistat VALUES(now(), 'test', '', '', 10), (now(), 'test', '', '', 10), (now(), 'test', '', '', 20), (now(), 'test', '', '', 30);
続いて、ターゲットテーブルの hits 列が正しく合計されているか確認します。FINAL 修飾子を使うと、SummingMergeTree で未マージの行がある場合でも最終的な合計を返してくれます:
SELECT hits FROM wikistat_top_projects FINAL WHERE (project = 'test') AND (date = date(now())) ┌─hits─┐ │ 70 │ └──────┘ 1 row in set. Elapsed: 0.005 sec. Processed 7.15 thousand rows, 89.37 KB (1.37 million rows/s., 17.13 MB/s.)
本番環境では、大規模テーブルに対して FINAL を頻繁に使うのは避け、代わりにクエリ時に sum(hits) で集計する方法が推奨されます。また、挿入時のマージ挙動を制御する optimize_on_insert 設定も確認するとよいでしょう。
Materialized Viewで集計を高速化する
先述のとおり、Materialized Viewはクエリのパフォーマンスを向上させる手段です。分析系のクエリで一般的に行われるさまざまな集計(たとえば sum() 以外も)を高速化できます。SummingMergeTree は合計値を追跡するのに便利ですが、より複雑な集計が必要な場合は AggregatingMergeTree を使うことができます。
たとえば次のようなクエリを頻繁に実行しているとします:
SELECT toDate(time) AS date, min(hits) AS min_hits_per_hour, max(hits) AS max_hits_per_hour, avg(hits) AS avg_hits_per_hour FROM wikistat WHERE project = 'en' GROUP BY date
これは特定のプロジェクトについて、日別に「1 時間単位での hits の最小値、最大値、平均値」を求めるクエリです:
┌───────date─┬─min_hits_per_hour─┬─max_hits_per_hour─┬──avg_hits_per_hour─┐ │ 2015-05-01 │ 1 │ 36802 │ 4.586310181621408 │ │ 2015-05-02 │ 1 │ 23331 │ 4.241388590780171 │ │ 2015-05-03 │ 1 │ 24678 │ 4.317835245126423 │ ... └────────────┴───────────────────┴───────────────────┴────────────────────┘ 38 rows in set. Elapsed: 8.970 sec. Processed 994.11 million rows
なお、もともと生データが「1 時間単位」で集計されていると仮定しています。
この集計結果をMaterialized Viewで保存しておくことで、必要なときに高速に取り出せます。state コンビネータを使うと、最終的な集計値ではなく「内部の中間集計状態」を保存でき、すべての元データを保持する必要がありません。手順としては、Materialized Viewを作るときに *State() 関数を使い、クエリ時に対応する *Merge() 関数を使って実際の値を計算します:
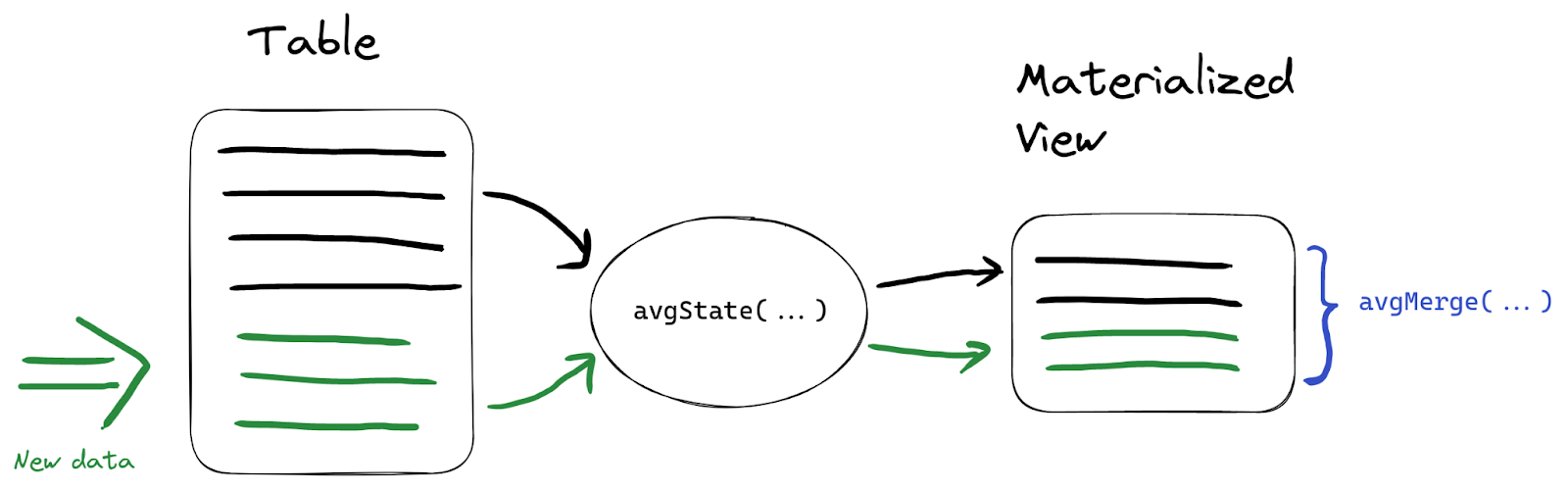
ここでは min, max, avg を例にします。新しく作るターゲットテーブルでは AggregateFunction 型を使って「中間集計状態」を保存します:
CREATE TABLE wikistat_daily_summary ( `project` String, `date` Date, `min_hits_per_hour` AggregateFunction(min, UInt64), `max_hits_per_hour` AggregateFunction(max, UInt64), `avg_hits_per_hour` AggregateFunction(avg, UInt64) ) ENGINE = AggregatingMergeTree ORDER BY (project, date); Ok. CREATE MATERIALIZED VIEW wikistat_daily_summary_mv TO wikistat_daily_summary AS SELECT project, toDate(time) AS date, minState(hits) AS min_hits_per_hour, maxState(hits) AS max_hits_per_hour, avgState(hits) AS avg_hits_per_hour FROM wikistat GROUP BY project, date
これを初期化するために、既存のデータを一括で挿入します:
INSERT INTO wikistat_daily_summary SELECT project, toDate(time) AS date, minState(hits) AS min_hits_per_hour, maxState(hits) AS max_hits_per_hour, avgState(hits) AS avg_hits_per_hour FROM wikistat GROUP BY project, date 0 rows in set. Elapsed: 33.685 sec. Processed 994.11 million rows
クエリ時には、対応する Merge コンビネータを使って値を取り出します:
SELECT date, minMerge(min_hits_per_hour) min_hits_per_hour, maxMerge(max_hits_per_hour) max_hits_per_hour, avgMerge(avg_hits_per_hour) avg_hits_per_hour FROM wikistat_daily_summary WHERE project = 'en' GROUP BY date
すると、同じ結果が数千倍速く得られます:
┌───────date─┬─min_hits_per_hour─┬─max_hits_per_hour─┬──avg_hits_per_hour─┐ │ 2015-05-01 │ 1 │ 36802 │ 4.586310181621408 │ │ 2015-05-02 │ 1 │ 23331 │ 4.241388590780171 │ │ 2015-05-03 │ 1 │ 24678 │ 4.317835245126423 │ ... └────────────┴───────────────────┴───────────────────┴────────────────────┘ 32 rows in set. Elapsed: 0.005 sec. Processed 9.54 thousand rows, 1.14 MB (1.76 million rows/s., 209.01 MB/s.)
他の 集計関数 も同様に State/Merge コンビネータを使って保存・計算できます。
ストレージ最適化のためのデータ圧縮
場合によっては「最新の数日間は生データが必要だが、それ以降は集計した履歴データで十分」という運用をしたいことがあります。そういったときには、ソーステーブルに対してMaterialized View+TTL を組み合わせると、有効なストレージ管理ができます。
また、最適なスキーマ を定義しておけば、ストレージ使用量をさらに削減できる可能性があります。たとえば、wikistat テーブルのデータを「月ごとに集約したものだけ」保存したい場合を考えます:
CREATE MATERIALIZED VIEW wikistat_monthly_mv TO wikistat_monthly AS SELECT toDate(toStartOfMonth(time)) AS month, path, sum(hits) AS hits FROM wikistat GROUP BY path, month
1 時間ごとの生データを持つオリジナルテーブルと比べると、集約されたMaterialized Viewはディスク使用量が約 3 倍の差になります:
注意点として、行数が少なくとも 10 倍以上減るようなケースでないと、単に元データを圧縮するだけでも十分近い効率を得られることがあります。ClickHouse の強力な圧縮とエンコードによって、必ずしも集約が不要な場合もあるので検討が必要です。
月単位の集約テーブルを用意したら、元テーブルには 1 週間を過ぎたデータを削除する TTL を設定することで、古い生データを自動で削除できます:
ALTER TABLE wikistat MODIFY TTL time + INTERVAL 1 WEEK
データのバリデーションとフィルタリング
Materialized Viewがよく使われる用途の一つとして、データを挿入直後に検証(バリデーション)して、特定の行を除外したり別のテーブルに保存したりするパターンがあります。
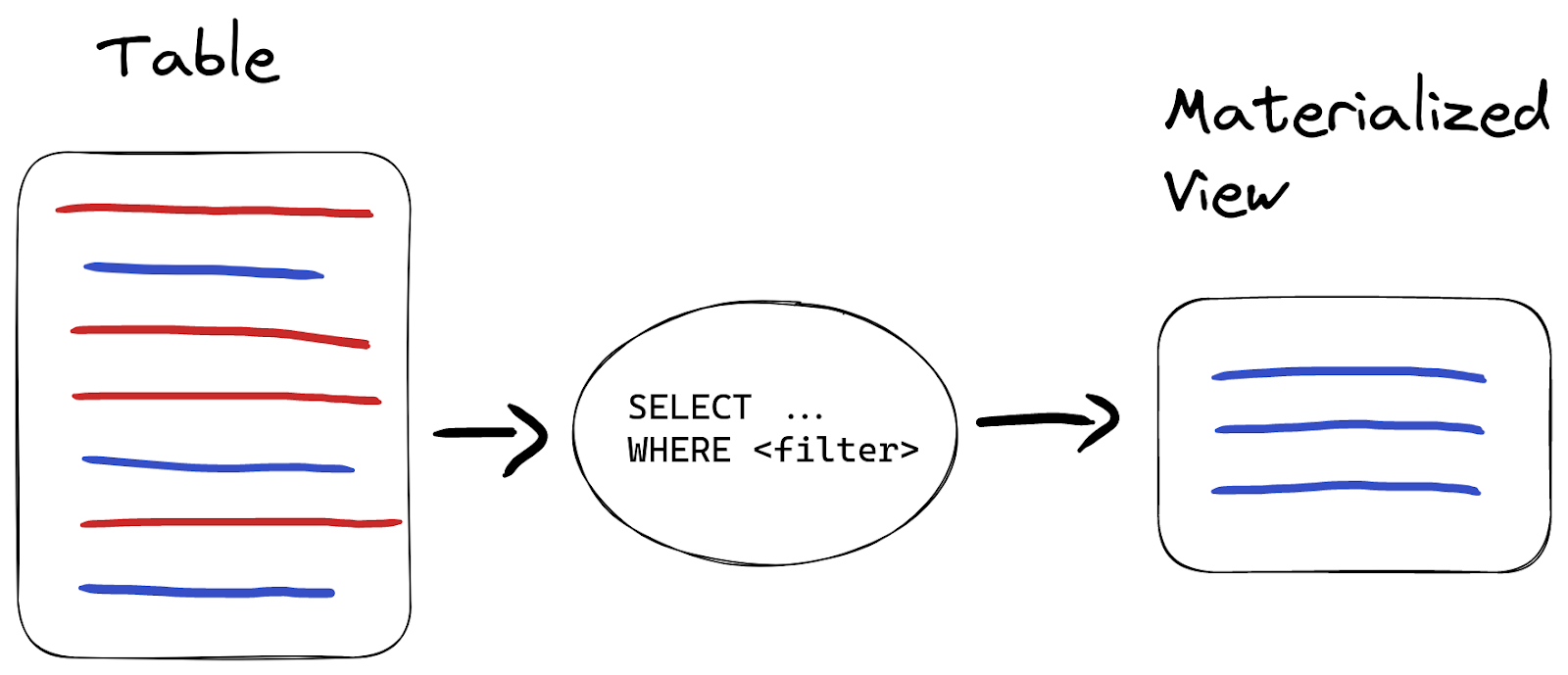
たとえば、path に不適切な文字が含まれる行を「クリーンなデータ」に含めたくないとしましょう。データの約 1% が該当するとします:
SELECT count(*) FROM wikistat WHERE NOT match(path, '[a-z0-9\\-]') LIMIT 5 ┌──count()─┐ │ 12168918 │ └──────────┘ 1 row in set. Elapsed: 46.324 sec. Processed 994.11 million rows, 28.01 GB (21.46 million rows/s., 604.62 MB/s.)
こうしたバリデーションやフィルタリングを行うには、クリーンデータ専用のテーブルとソーステーブルの 2 つがあれば十分です。Materialized Viewのターゲットテーブルを「最終的なクリーンなデータを持つテーブル」として使います。ソーステーブルの方は、Null エンジンを使うことで実際のデータを保存しないようにできます。
CREATE TABLE wikistat_src ( `time` DateTime, `project` LowCardinality(String), `subproject` LowCardinality(String), `path` String, `hits` UInt64 ) ENGINE = Null
次に、バリデーション用のクエリを持つMaterialized Viewを作成します:
CREATE TABLE wikistat_clean AS wikistat; Ok. CREATE MATERIALIZED VIEW wikistat_clean_mv TO wikistat_clean AS SELECT * FROM wikistat_src WHERE match(path, '[a-z0-9\\-]')
この状態でデータを挿入すると、wikistat_src は空のままです:
INSERT INTO wikistat_src SELECT * FROM s3('https://ClickHouse-public-datasets.s3.amazonaws.com/wikistat/partitioned/wikistat*.native.zst') LIMIT 1000
確認してみましょう:
SELECT count(*) FROM wikistat_src ┌─count()─┐ │ 0 │ └─────────┘
一方で、wikistat_clean には条件を満たす行だけが保存されています:
SELECT count(*) FROM wikistat_clean ┌─count()─┐ │ 58 │ └─────────┘
1000 行のうち 58 行だけが条件をクリアし、残りの 942 行は挿入時に除外されました。
データを複数のテーブルに振り分ける
Materialized Viewを使えば、条件に応じてデータを別のテーブルに振り分けることも簡単です:
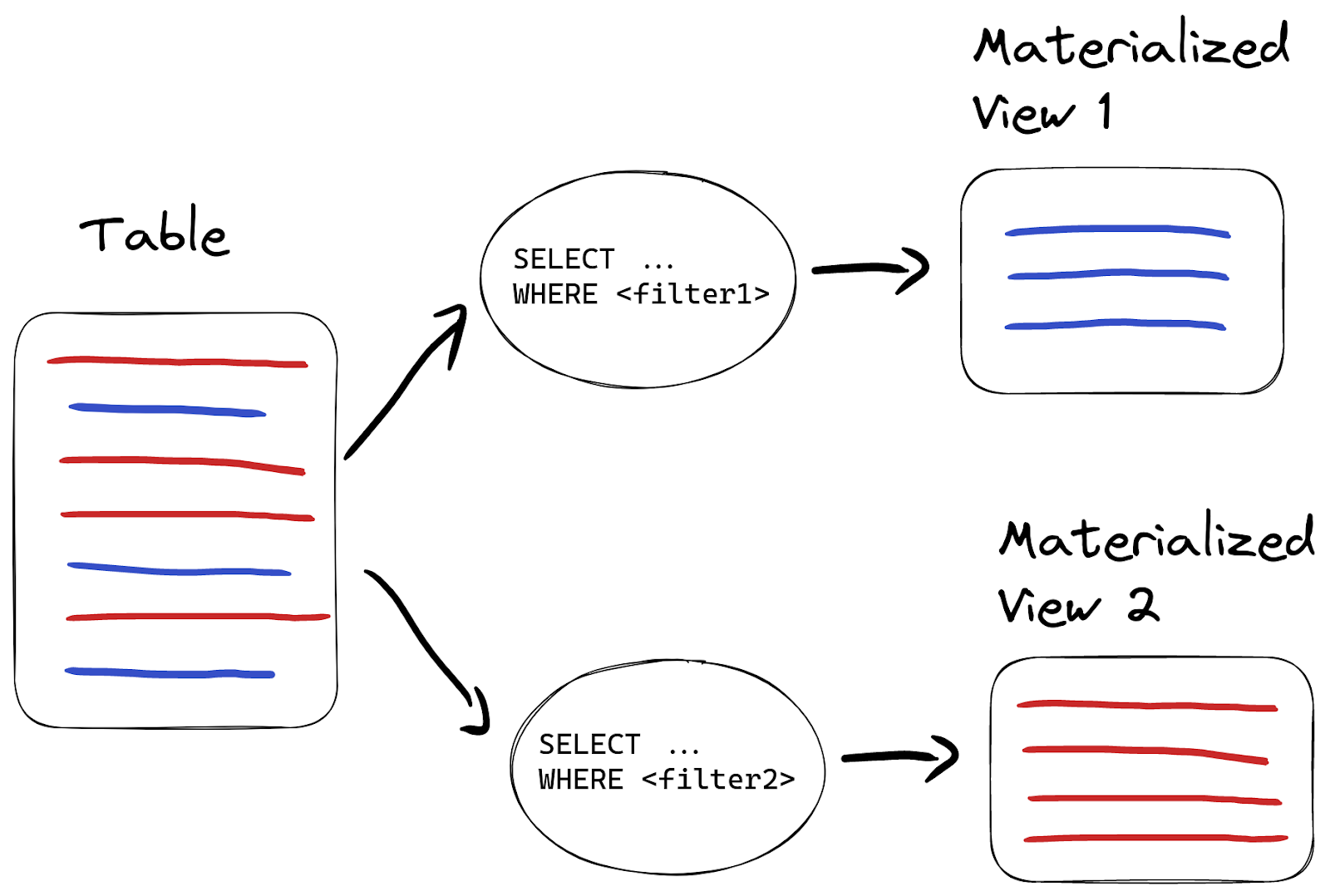
たとえば、不正データを削除するのではなく、別テーブルに保存したい場合は、別のクエリを持つMaterialized Viewをもう一つ作成します:
CREATE TABLE wikistat_invalid AS wikistat; Ok. CREATE MATERIALIZED VIEW wikistat_invalid_mv TO wikistat_invalid AS SELECT * FROM wikistat_src WHERE NOT match(path, '[a-z0-9\\-]')
同じソーステーブルに対して複数のMaterialized Viewを設定すると、アルファベット順に処理されます。1 つのソーステーブルに対してMaterialized Viewを作りすぎると挿入パフォーマンスが下がるため、やはり数には注意しましょう。
先ほどと同じデータを再度挿入すると、wikistat_invalid には不正データ 942 行が保存されているはずです:
SELECT count(*) FROM wikistat_invalid ┌─count()─┐ │ 942 │ └─────────┘
データの変換
Materialized Viewはクエリ結果に基づくので、ClickHouse の豊富な関数を使ってデータを自由に変換できます。たとえば、project, subproject, path をまとめて page にし、time を date と hour に分割するような変換を挿入時に自動で行うことも可能です:
CREATE TABLE wikistat_human ( `date` Date, `hour` UInt8, `page` String ) ENGINE = MergeTree ORDER BY (page, date); Ok. CREATE MATERIALIZED VIEW wikistat_human_mv TO wikistat_human AS SELECT date(time) AS date, toHour(time) AS hour, concat(project, if(subproject != '', '/', ''), subproject, '/', path) AS page, hits FROM wikistat
こうすると、以後 wikistat に挿入されるたびに変換後のデータが wikistat_human に自動的に蓄積されます:
┌───────date─┬─hour─┬─page──────────────────────────┬─hits─┐ │ 2015-11-08 │ 8 │ en/m/Angel_Muñoz_(politician) │ 1 │ │ 2015-11-09 │ 3 │ en/m/Angel_Muñoz_(politician) │ 1 │ └────────────┴──────┴───────────────────────────────┴──────┘
本番でMaterialized Viewを作成するには
本番環境など、すでに大量のデータがあるテーブルに対してMaterialized Viewを作成する場合は、以下のような手順が一般的です:
- ソーステーブルへの書き込みを一時停止する
- Materialized Viewを作成する
- ソーステーブルの既存データをターゲットテーブルへ反映(INSERT)する
- ソーステーブルへの書き込みを再開する
あるいは、Materialized Viewを作る際に未来の時点を指定しておく方法もあります:
CREATE MATERIALIZED VIEW mv TO target_table AS SELECT … FROM soruce_table WHERE date > `$todays_date`
ここで $todays_date は特定の日付を入れてください。そうすると、Materialized Viewはその日付以降のデータに対してだけ機能するので、その前の日付のデータは手動で以下のように INSERT すればよいことになります:
INSERT INTO target_table SELECT ... FROM soruce_table WHERE date <= `$todays_date`
Materialized View と JOIN
Materialized Viewは SQL クエリの結果に基づくため、JOIN を含むあらゆる機能を利用できます。ただし、大きなテーブル同士の JOIN は挿入パフォーマンスを大きく下げる可能性があるため注意が必要です。
たとえば、wikistat データセットに対応するページタイトルを持つ wikistat_titles テーブルがあるとします:
CREATE TABLE wikistat_titles ( `path` String, `title` String ) ENGINE = MergeTree ORDER BY path
このテーブルは、path と対応するページのタイトルを保存しています:
SELECT * FROM wikistat_titles ┌─path─────────┬─title────────────────┐ │ Ana_Sayfa │ Ana Sayfa - artist │ │ Bruce_Jenner │ William Bruce Jenner │ └──────────────┴──────────────────────┘
ここで、wikistat テーブルと wikistat_titles を path 列で JOIN した結果をMaterialized Viewに保存してみましょう:
CREATE TABLE wikistat_with_titles ( `time` DateTime, `path` String, `title` String, `hits` UInt64 ) ENGINE = MergeTree ORDER BY (path, time); Ok. CREATE MATERIALIZED VIEW wikistat_with_titles_mv TO wikistat_with_titles AS SELECT time, path, title, hits FROM wikistat AS w INNER JOIN wikistat_titles AS wt ON w.path = wt.path
INNER JOIN を使っているので、wikistat_titles テーブルにある path と一致する行だけが対象になります:
SELECT * FROM wikistat_with_titles LIMIT 5 ┌────────────────time─┬─path──────┬─title──────────────┬─hits─┐ │ 2015-05-01 01:00:00 │ Ana_Sayfa │ Ana Sayfa - artist │ 5 │ │ 2015-05-01 01:00:00 │ Ana_Sayfa │ Ana Sayfa - artist │ 7 │ │ 2015-05-01 01:00:00 │ Ana_Sayfa │ Ana Sayfa - artist │ 1 │ │ 2015-05-01 01:00:00 │ Ana_Sayfa │ Ana Sayfa - artist │ 3 │ │ 2015-05-01 01:00:00 │ Ana_Sayfa │ Ana Sayfa - artist │ 653 │ └─────────────────────┴───────────┴────────────────────┴──────┘
続いて、wikistat テーブルに新しい行を挿入してみましょう:
INSERT INTO wikistat VALUES(now(), 'en', '', 'Ana_Sayfa', 123); 1 row in set. Elapsed: 1.538 sec.
上記の挿入がやや時間を要している(1.538 sec)ことに注目してください。Materialized Viewが JOIN を伴うため、挿入時に JOIN が実行されるからです。結果として、新しい行は wikistat_with_titles に保存されます:
SELECT * FROM wikistat_with_titles ORDER BY time DESC LIMIT 3 ┌────────────────time─┬─path─────────┬─title────────────────┬─hits─┐ │ 2023-01-03 08:43:14 │ Ana_Sayfa │ Ana Sayfa - artist │ 123 │ │ 2015-06-30 23:00:00 │ Bruce_Jenner │ William Bruce Jenner │ 115 │ │ 2015-06-30 23:00:00 │ Bruce_Jenner │ William Bruce Jenner │ 55 │ └─────────────────────┴──────────────┴──────────────────────┴──────┘
では、wikistat_titles テーブル側に新しいデータを挿入するとどうなるでしょうか:
INSERT INTO wikistat_titles VALUES('Academy_Awards', 'Oscar academy awards');
wikistat テーブルに対応する行を挿入していないので、Materialized Viewには何も反映されません:
SELECT * FROM wikistat_with_titles WHERE path = 'Academy_Awards' 0 rows in set. Elapsed: 0.003 sec.
これは、Materialized Viewが「ソーステーブルへの挿入」をトリガーとして動作し、JOIN 先など外部のテーブルの挿入はトリガーされないためです。JOIN に限らず、他テーブルへの IN SELECT などでも同様です。
ここでは wikistat がソーステーブルで、wikistat_titles は単に JOIN されるテーブルです:
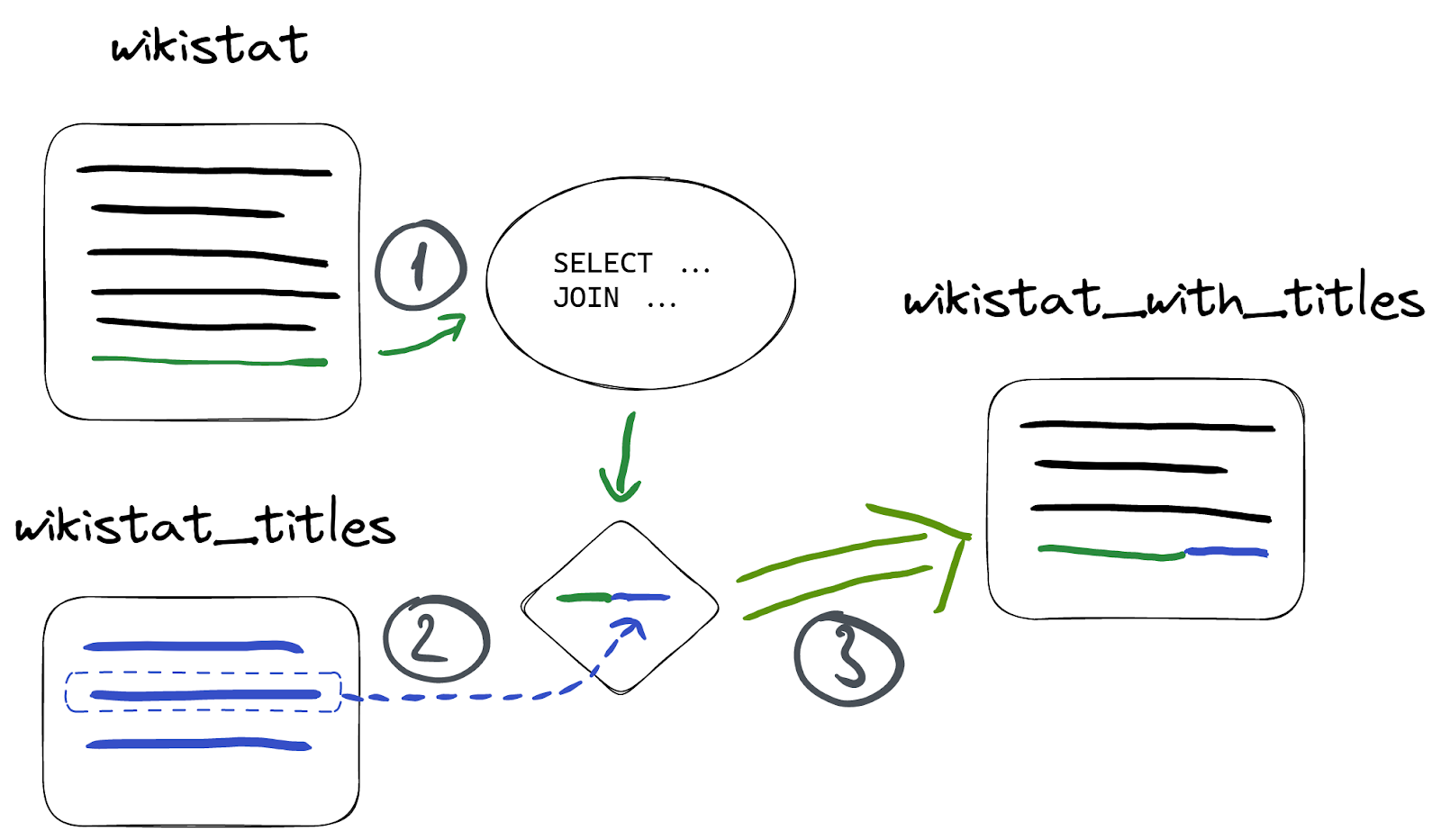
そのため、wikistat にレコードを挿入しないかぎりMaterialized Viewは更新されません。実際に wikistat に新たな行を挿入すると:
INSERT INTO wikistat VALUES(now(), 'en', '', 'Academy_Awards', 456);
Materialized Viewにレコードが追加されます:
SELECT * FROM wikistat_with_titles WHERE path = 'Academy_Awards' ┌────────────────time─┬─path───────────┬─title────────────────┬─hits─┐ │ 2023-01-03 08:56:50 │ Academy_Awards │ Oscar academy awards │ 456 │ └─────────────────────┴────────────────┴──────────────────────┴──────┘
注意: このように大きなテーブル同士の JOIN をMaterialized Viewで使うと、挿入時のパフォーマンスが大きく低下する可能性があります。より効率的な方法としては、dictionaries を検討することも一案です。
まとめ
本記事では、Materialized Viewが ClickHouse でクエリパフォーマンスを向上させたり、データ管理機能を拡張したりするうえで非常に強力なツールであることを紹介しました。Materialized Viewでは JOIN を使うことも可能です。シンプルな変換やフィルタリングだけであれば、マテリアライズドカラムを使うのも手ですが、より高度な集計や振り分け処理にはMaterialized Viewが適しています。


