Get started with ClickHouse Cloud today and receive $300 in credits. To learn more about our volume-based discounts, contact us or visit our pricing page.
Blog / Engineering
Vector Search with ClickHouse - Part 2
Dale McDiarmid
May 31, 2023 - 49 minutes read
Table of Contents
Introduction
This blog post continues our series on vector search, building on the previous post where we provided an overview of what vector search is, its relation to historical inverted index-based approaches, possible use cases for which it currently delivers value, and some high-level implementation approaches. In this post, we explore vector search in relation to ClickHouse in detail through practical examples as well as answering the question, "When should I use ClickHouse for vector search?"
For our examples, we utilize a ClickHouse Cloud cluster with a total of 60 cores and 240GB of RAM per node. These examples should, however, be reproducible on an equivalently sized self-managed cluster. Alternatively, start your ClickHouse Cloud cluster today, and receive $300 of credit. Let us worry about the infrastructure, and get querying!
When should I use ClickHouse for vector search?
ClickHouse is a real-time OLAP database with full SQL support and a wide range of functions to assist users in writing analytical queries. Some of these functions and data structures perform distance operations between vectors, enabling ClickHouse to be used as a vector database.
Due to the fully parallelized query pipeline, ClickHouse can process vector search operations very quickly, especially when performing exact matching through a linear scan over all rows, delivering processing speed comparable to dedicated vector databases.
High compression levels, tunable through custom compression codecs, enable very large datasets to be stored and queried. ClickHouse is not memory-bound, allowing multi-TB datasets containing embeddings to be queried.
The capabilities for computing the distance between two vectors are just another SQL function and can be effectively combined with more traditional SQL filtering and aggregation capabilities. This allows vectors to be stored and queried alongside metadata, and even rich text, enabling a broad array of use cases and applications.
Finally, experimental ClickHouse capabilities like Approximate Nearest Neighbour (ANN) indices support faster approximate matching of vectors and provide a promising development aimed to further enhance the vector matching capabilities of ClickHouse.
In summary, ClickHouse is an effective platform for vector search when any of the following are true:
- You wish to combine vector matching with filtering on metadata and/or aggregation or join capabilities
- You need to perform linear distance matching over very large vector datasets and wish to parallelize and distribute this work across many CPU cores with no additional work or configuration
- You need to match on vector datasets of a size where relying on memory-only indices is not viable either due to cost or availability of hardware
- You would benefit from full SQL support when querying your vectors
- You have an existing embedding generation pipeline that produces your vectors and do not require this capability to be native to your storage engine
- You already have related data in ClickHouse and do not wish to incur the overhead and cost of learning another tool for a few million vectors
- You principally need fast parallelized exact matching of your vectors and do not need a production implementation of ANN (yet!)
- You're an experienced or curious ClickHouse user and trust us to improve our vector matching capabilities and wish to be part of this journey
While this covers a wide range of use cases, there are some instances where ClickHouse may be less appropriate as a vector storage engine, and you may wish to consider alternatives such as Faiss, or a dedicated vector database. Today ClickHouse may provide fewer benefits as a vector search engine if:
- Your vector dataset is small and easily fits in memory. While ClickHouse can easily accomplish vector search for small datasets, it may be more powerful than is needed in this case.
- You have no additional metadata with the vectors and need distance matching and sorting only. If joining vector search results with other metadata isn’t useful, and your dataset is small, then as described above, ClickHouse may be more powerful than you really need.
- You have a very high QPS, greater than several thousand per second. Typically, for these use cases, the dataset will fit in memory, and matching times of a few ms are required. While ClickHouse can serve these use cases, a simple in-memory index is probably sufficient.
- You need a solution that includes embedding generation capabilities out-of-the-box, where a model is integrated at insert and query time. Vector databases, such as Weaviate, are specifically designed for this use case and may be more appropriate given these needs.
With this in mind, let's explore the vector capabilities of ClickHouse.
Setting up an example
The LAION dataset
As discussed in our previous post, vector search operates on embeddings – vectors representing a contextual meaning. Embeddings are generated by passing raw content, such as images or text, through a pre-trained machine learning model.
For this post, we used a prepared set of embeddings, available publicly for download, called the LAION 5 billion test set. We selected this dataset because we believe at the time of writing this to be the largest available dataset of pre-computed embeddings available for testing. It consists of embeddings with a dimension of 768 for several billion public images on the internet and their captions, generated through a public crawl of the internet. Created with the explicit purpose of testing vector search at scale, it also includes metadata that is in turn useful for illustrating how to combine general purpose analytics capabilities of ClickHouse with vector search.
In the LAION dataset, embeddings have been generated for each image and its associated caption - giving us two embeddings for each object. For this post, we have focused on the English subset only, which consists of a reduced 2.2 billion objects. Although each of these objects has two embeddings, one for its image and one caption, respectively, we store each pair as a single row in ClickHouse, giving us almost 2.2 billion rows in total and 4.4 billion vectors. For each row, we include the metadata as columns, which captures information such as the image dimensions, the similarity of the image, and caption embedding. This similarity, a cosine distance, allows us to identify objects where the caption and image do not conceptually align, potentially filtering these out in queries.
We want to acknowledge the effort required by the original authors to collate this dataset and produce the embeddings for public use. We recommend reading the full process for generating this dataset, which overcame a number of challenging data engineering challenges, such as downloading and resizing billions of images efficiently and in a reasonable time and at an acceptable cost.
Using the CLIP model to generate embeddings
These LAION embeddings were generated with the ViT-L/14 model, trained by LAION using openCLIP, an open source implementation of the CLIP model developed by OpenAI. This isn't a cheap process! On 400 million images, this took around 30 days and needed 592 V100 GPUs (about $1M on AWS on-demand instances).
CLIP (Contrastive Language–Image Pre-training) is a multi-modal model, which means that it is designed to train multiple related types of data, such as images and associated text. CLIP has proved effective at learning visual representations of text with promising results in OCR, geolocalisation, and action recognition. For encoding of the images, the authors of CLIP used Resnet50 and Vision Transformer (ViT), and for the encoding of the text used a transformer similar to GPT-2 . Resulting embeddings are represented as two separate sets of vectors.
The key outcome of the training process is that the embeddings for the two data types are comparable – if the vectors for an image and the caption are close, then they can be considered conceptually similar. A good model like CLIP would result in close embeddings with respect to distance, or a high value close to 1 for cosine similarity, for an image vector and its associated caption vector. This is illustrated below in the image below, where T1 is the embedded representation of the 1st image's caption, and I1 is the encoding of the image itself. This means we want to maximize the diagonal of this matrix during the training process, where our images and text coincide.
As a post-processing step, the authors discarded images where the cosine similarity with the text caption was less than 0.28, thus filtering out potentially poor quality results where the caption and image don’t align. Further filtering by image size, caption length, possible illegality, and removal of duplicates reduced the total dataset from over 5 billion to 2.2 billion.
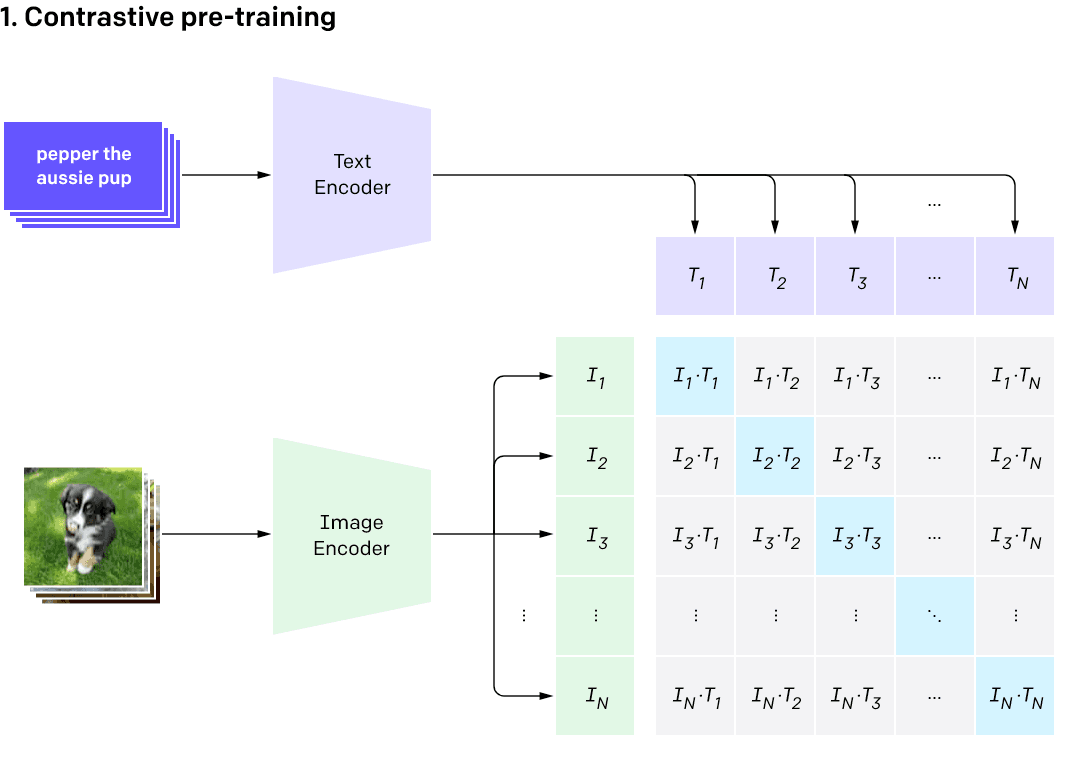 Credit: https://openai.com/research/clip
Credit: https://openai.com/research/clip
Preparing the data for loading
The LAION dataset is downloadable from a number of sources. Selecting the English subset, we utilized the version hosted by Hugging Face. This service relies on Git Large File Storage (LFS), which requires a client to be installed to download files. Once installed, downloading the data requires a single command. For this, ensure you have at least 20TB of disk space available.
git lfs install
git clone https://huggingface.co/datasets/laion/laion2b-en-vit-l-14-embeddings
Download consists of three folders; two of these contain embeddings in the format npy (effectively a multi-dimensional array format) for the images and captions, and the third directory contains Parquet files containing the metadata for each image and caption pair.
ubuntu@ip-172-31-2-70:/data$ ls -l ./laion2b-en-vit-l-14-embeddings
total 456
drwxrwxr-x 2 ubuntu ubuntu 77824 May 16 12:28 img_emb
drwxrwxr-x 2 ubuntu ubuntu 110592 May 16 12:27 metadata
drwxrwxr-x 2 ubuntu ubuntu 270336 May 16 12:28 text_emb
To load this data into ClickHouse, we wanted to produce a single row per embedding pair with the metadata for enrichment. This would require a process that merged the respective embedding and metadata for each object. Considering that vectors in ClickHouse can be represented as an array of Floats, a JSON row produced as a result of this process may look like the following:
{
"key": "196060024",
"url": "https://cdn.shopify.com/s/files/1/1194/1070/products/[email protected]?v=1477414012",
"caption": "MERCEDES BENZ G65 RIDE-ON TOY CAR WITH PARENTAL REMOTE | CHERRY",
"similarity": 0.33110910654067993,
"width": "220",
"height": "147",
"original_width": "220",
"original_height": "147",
"status": "success",
"NSFW": "UNLIKELY",
"exif": {
"Image Orientation": "Horizontal (normal)",
"Image XResolution": "72",
"Image YResolution": "72",
"Image ResolutionUnit": "Pixels/Inch",
"Image YCbCrPositioning": "Centered",
"Image ExifOffset": "102",
"EXIF ExifVersion": "0210",
"EXIF ComponentsConfiguration": "YCbCr",
"EXIF FlashPixVersion": "0100",
"EXIF ColorSpace": "Uncalibrated",
"EXIF ExifImageWidth": "220",
"EXIF ExifImageLength": "147"
},
"text_embedding": [
0.025299072265625,
...
-0.031829833984375
],
"image_embedding": [
0.0302276611328125,
...
-0.00667572021484375
]
}
The full code for pre-processing the dataset can be found here. The final 2313 Parquet files generated as a result of this process consume around 5.9TB of disk space. We have combined these to produce a 6TB Parquet dataset our users can s3://datasets-documentation/laion/ and use to reproduce examples.
Storing vectors in ClickHouse
Loading resulting Parquet files into ClickHouse requires a few simple steps.
Schema and loading process
The following shows our table schema, with embeddings stored as Array(Float32) columns.
CREATE TABLE laion
(
`_file` LowCardinality(String),
`key` String,
`url` String,
`caption` String,
`similarity` Float64,
`width` Int64,
`height` Int64,
`original_width` Int64,
`original_height` Int64,
`status` LowCardinality(String),
`NSFW` LowCardinality(String),
`exif` Map(String, String),
`text_embedding` Array(Float32),
`image_embedding` Array(Float32),
`orientation` String DEFAULT exif['Image Orientation'],
`software` String DEFAULT exif['Image Software'],
`copyright` String DEFAULT exif['Image Copyright'],
`image_make` String DEFAULT exif['Image Make'],
`image_model` String DEFAULT exif['Image Model']
)
ENGINE = MergeTree
ORDER BY (height, width, similarity)
The exif column contains metadata we can later use for filtering and aggregation. We have mapped this as aMap(String,String) for flexibility and schema succinctness. This column contains over 100,000 unique meta labels. Accessing a sub key requires all of the keys to be loaded from the column, potentially slowing down some queries, so we have extracted five properties of interest to the root for later analytics using the DEFAULT syntax. For users interested in the full list of available meta properties, the following query can be used to identify available Map keys and their frequency:
SELECT
arrayJoin(mapKeys(exif)) AS keys,
count() AS c
FROM laion
GROUP BY keys
ORDER BY c DESC
LIMIT 10
Our schema also includes a _file column, denoting the original Parquet file from which this data is generated. This allows us to restart a specific file load should it fail during insertion into ClickHouse.
For future usage, we loaded this data into a public S3 bucket. To insert this data into ClickHouse, users can execute the following query:
INSERT INTO laion SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/laion/*.parquet')
This is a considerable amount of data to load, with an unoptimized load taking several hours. We recommend that users batch the loading process, to avoid interruptions such as network connectivity issues. Users can target specific subsets using glob patterns, e.g., s3(https://datasets-documentation.s3.eu-west-3.amazonaws.com/laion/00*.parquet). The _file column can be used to reconcile any loading issues by confirming the count in ClickHouse with that in the original Parquet files.
For our examples below, we have created tables of various sizes with a suffix denoting the number of rows; e.g., laion_100m contains 100 million rows. These are created with appropriate glob patterns.
INSERT INTO laion_sample (_file, key, url, caption, similarity, width, height, original_width, original_height, status, NSFW, exif, text_embedding, image_embedding) SELECT
_file,
key,
url,
caption,
similarity,
width,
height,
original_width,
original_height,
status,
NSFW,
exif,
text_embedding,
image_embedding
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/laion/*.parquet')
Storage performance with compression
The column-oriented structure of ClickHouse means the values for a column are sorted and written in sequence. The clustering of identical and similar values on disk typically leads to high compression ratios. ClickHouse even offers several schemas and codecs to allow users to tune their configuration based on the properties of their data. For arrays of floating point numbers, high compression is harder to achieve since the values of the embeddings have no domain-agnostic properties to exploit. The full 32-bit range is utilized, and for most codecs, the relation between adjacent values in an embedding is random. For this reason, we recommend the ZSTD codec for compressing embeddings. Below we show the compression ratio for our vector columns in four tables of increasing size: 1m, 10m, 100m, and 2b rows.
SELECT
table,
name,
formatReadableSize(sum(data_compressed_bytes)) AS compressed_size,
formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed_size,
round(sum(data_uncompressed_bytes) / sum(data_compressed_bytes), 2) AS ratio
FROM system.columns
WHERE (table IN ('laion_100m', 'laion_1m', 'laion_10m', 'laion_2b')) AND (name IN ('text_embedding', 'image_embedding'))
GROUP BY
table,
name
ORDER BY table DESC
┌─table──────┬─name────────────┬─compressed_size─┬─uncompressed_size─┬─ratio─┐
│ laion_1m │ text_embedding │ 1.60 GiB │ 2.50 GiB │ 1.56 │
│ laion_1m │ image_embedding │ 1.61 GiB │ 2.50 GiB │ 1.55 │
│ laion_10m │ text_embedding │ 18.36 GiB │ 28.59 GiB │ 1.56 │
│ laion_10m │ image_embedding │ 18.36 GiB │ 28.59 GiB │ 1.56 │
│ laion_100m │ text_embedding │ 181.64 GiB │ 286.43 GiB │ 1.58 │
│ laion_100m │ image_embedding │ 182.29 GiB │ 286.43 GiB │ 1.57 │
│ laion_1b │ image_embedding │ 1.81 TiB │ 2.81 TiB │ 1.55 │
│ laion_1b │ text_embedding │ 1.81 TiB │ 2.81 TiB │ 1.55 │
└────────────┴─────────────────┴─────────────────┴───────────────────┴───────┘
6 rows in set. Elapsed: 0.006 sec.
While compression rates can usually be influenced by primary key selection, this constant compression ratio of 1.56 is unlikely to be impacted by how the data is sorted. The compression level of the ZSTD codec can be increased from its default value of 1 in ClickHouse Cloud. This delivers around a 10% improvement, compressing our data by 1.71 on a 10 million row sample:
SELECT
table,
name,
formatReadableSize(sum(data_compressed_bytes)) AS compressed_size,
formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed_size,
round(sum(data_uncompressed_bytes) / sum(data_compressed_bytes), 2) AS ratio
FROM system.columns
WHERE (table IN ('laion_10m_zstd_3')) AND (name IN ('text_embedding', 'image_embedding'))
GROUP BY
table,
name
ORDER BY table DESC
┌─table────────────┬─name────────────┬─compressed_size─┬─uncompressed_size─┬─ratio─┐
│ laion_10m_zstd_3 │ text_embedding │ 16.68 GiB │ 28.56 GiB │ 1.71 │
│ laion_10m_zstd_3 │ image_embedding │ 16.72 GiB │ 28.56 GiB │ 1.71 │
└──────────────────┴─────────────────┴─────────────────┴───────────────────┴───────┘
2 rows in set. Elapsed: 0.026 sec.
Note that higher values for ZSTD will slow down compression and data insertion, although decompression speeds should remain reasonably constant (around 20% variance)).
The compression of floating point numbers is an area of research, with several lossy candidates based on quantization, such as the SZ algorithm being possible additions to ClickHouse. Other options include reducing the precision of our floating points to 16 bits. We discuss this below in the “Improving compression” section.
Searching vectors in ClickHouse
As we covered in Part 1 of this series, performing vector search means comparing an input vector against a repository of vectors to find the closest match.
The input vector represents the concept of interest. In our case, this is either an encoded image or caption. The repository of vectors represents other images and their captions we wish to compare against.
When performing the search, the vectors are compared for proximity or distance. Two vectors that are close in distance represent similar concepts. The two vectors that are the closest in distance are the most similar in the set.
Choosing a distance function
Given the high dimensionality of vectors, there are many ways to compare distance. These different mechanisms are referred to as distance functions.
ClickHouse supports a wide range of distance functions - you can choose which is most appropriate for you, given your use case. For this post, we focus on two which are very commonly used in vector search:
- Cosine Distance -
cosineDistance(vector1, vector2)- This gives us a Cosine distance between 2 vectors (1 - cosine similarity). More specifically, this measures the cosine of the angle between two vectors, i.e. the dot product divided by the length. This produces a value between -1 and 1, where 1 indicates the two embeddings are proportional and thus conceptually identical. A column name and input embedding can be parsed for vector search. This function is particularly relevant if the vectors have not been normalized, as well as delivering a bounded range useful for filtering. - L2 Distance-
L2Distance(vector1, vector2)- This measures the L2 distance between 2 points. Effectively this is the Euclidean distance between two input vectors, i.e. the length of the line between the points represented by the vectors. The lower the distance, the more conceptually similar the source objects.
Both functions compute a score that is used to compare vector embeddings. For our pre-trained CLIP model, L2 Distance represents the most appropriate distance function based on the internal scoring used for the official examples.
For a full list of available distance and vector normalization functions, see here. We would love to hear how you utilize these to search your embeddings!
Generating an input vector
Now that we’ve identified which distance function we’ll be using, we need to transform the input (the image or caption we want to search) into a vector embedding.
This requires us to invoke the CLIP model. This is easily achieved through a simple Python script. The instructions for installing the dependencies for this script can be found here. We show this script below:
#!/usr/bin/python3
import argparse
from PIL import Image
import clip
import torch
if __name__ == '__main__':
parser = argparse.ArgumentParser(
prog='generate',
description='Generate CLIP embeddings for images or text')
group = parser.add_mutually_exclusive_group(required=True)
group.add_argument('--text', required=False)
group.add_argument('--image', required=False)
parser.add_argument('--limit', default=1)
parser.add_argument('--table', default='laion_1m')
args = parser.parse_args()
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"using {device}")
device = torch.device(device)
model, preprocess = clip.load("ViT-L/14")
model.to(device)
images = []
if args.text:
inputs = clip.tokenize(args.text)
with torch.no_grad():
print(model.encode_text(inputs)[0].tolist())
elif args.image:
image = preprocess(Image.open(args.image)).unsqueeze(0).to(device)
with torch.no_grad():
print(model.encode_image(image)[0].tolist())
This version of the script accepts either text or an image path as input, outputting the embedding to the command line. Note that this will exploit CUDA-enabled GPUs if present. This can make a dramatic difference to the generation time - when tested on a Mac M1 2021, the generation time for 100 captions takes around 6 secs vs 1 sec on a p3.2xlarge with 1 GPU core.
As an example, let’s convert the text "a sleepy ridgeback dog" into an embedding. For purposes of brevity, we have cropped the full embedding result which can be found here.
python generate.py --text "a sleepy ridgeback dog"
[0.5736801028251648, 0.2516217529773712, ..., -0.6825592517852783]
We now have a vector embedding that represents the text “a sleepy ridgeback dog.” This is our search input vector. We can now compare this input vector against our repository of vector embeddings to find images and their captions that represent conceptually similar things.
Putting it all together
The query below searches for conceptually similar embeddings, and sorts them by distance. Embeddings are stored in the image_embedding column. Distance is stored as similarity. We filter out any distances that are greater than 0.2 to reduce noise.
SELECT
url,
caption,
L2Distance(image_embedding, [0.5736801028251648, 0.2516217529773712, ..., -0.6825592517852783]) AS score
FROM laion_10m WHERE similarity >= 0.2
ORDER BY score ASC
LIMIT 2
FORMAT Vertical
Row 1:
──────
url: https://thumb9.shutterstock.com/image-photo/stock-photo-front-view-of-a-cute-little-young-thoroughbred-african-rhodesian-ridgeback-hound-dog-puppy-lying-in-450w-62136922.jpg
caption: Front view of a cute little young thoroughbred African Rhodesian Ridgeback hound dog puppy lying in the woods outdoors and staring.
score: 12.262665434714496
Row 2:
──────
url: https://m.psecn.photoshelter.com/img-get2/I0000_1Vigovbi4o/fit=180x180/fill=/g=G0000x325fvoXUls/I0000_1Vigovbi4o.jpg
caption: SHOT 1/1/08 3:15:27 PM - Images of Tanner a three year-old male Vizsla sleeping in the sun on the couch in his home in Denver, Co. The Hungarian Vizsla, is a dog breed originating in Hungary. Vizslas are known as excellent hunting dogs, and also have a level personality making them suited for families. The Vizsla is a medium-sized hunting dog of distinguished appearance and bearing. Robust but rather lightly built, they are lean dogs, have defined muscles, and are similar to a Weimaraner but smaller in size. The breed standard calls for the tail to be docked to two-thirds of its original length in smooth Vizslas and to three-fourths in Wirehaired Vizslas..(Photo by Marc Piscotty/ (c) 2007)
score: 12.265194306913513
2 rows in set. Elapsed: 1.595 sec. Processed 9.92 million rows, 32.52 GB (6.22 million rows/s., 20.38 GB/s.)
The results show that our input vector “a sleepy ridgeback dog” is most conceptually similar to a photo in the dataset of a African Rhodesian Ridgeback hound, and also very conceptually similar to an image of a sleeping hunting dog.

My Dog Kibo
To further demonstrate the utility of these models, as an alternative to searching with text, we could start with an image of a sleeping dog, and search for similar images that way. We generate an input vector that represents this photo, and search for conceptually similar results.
To do so, we repeat the above query using the text_embedding column. The full embedding can be found here.
python generate.py --image images/ridgeback.jpg
[0.17179889976978302, 0.6171532273292542, ..., -0.21313616633415222]
SELECT
url,
caption,
L2Distance(text_embedding, [0.17179889976978302, ..., -0.21313616633415222]
) AS score
FROM laion_10m WHERE similarity >= 0.2
ORDER BY score ASC
LIMIT 2
FORMAT Vertical
Row 1:
──────
url: https://i.pinimg.com/236x/ab/85/4c/ab854cca81a3e19ae231c63f57ed6cfe--submissive--year-olds.jpg
caption: Lenny is a 2 to 3 year old male hound cross, about 25 pounds and much too thin. He has either been neglected or on his own for a while. He is very friendly if a little submissive, he ducked his head and tucked his tail a couple of times when I...
score: 17.903361349936052
Row 2:
──────
url: https://d1n3ar4lqtlydb.cloudfront.net/c/a/4/2246967.jpg
caption: American Pit Bull Terrier/Rhodesian Ridgeback Mix Dog for adoption in San Clemente, California - MARCUS = Quite A Friendly Guy!
score: 17.90681696075351
2 rows in set. Elapsed: 1.516 sec. Processed 9.92 million rows, 32.52 GB (6.54 million rows/s., 21.45 GB/s.)
For convenience, we’ve provided a simple result generator search.py, which encodes the passed image or text and executes the query, rendering the query results as a local html file. This file is then automatically opened in the local browser. The result file for the above query is shown below:
python search.py search --image images/ridgeback.jpg --table laion_10m
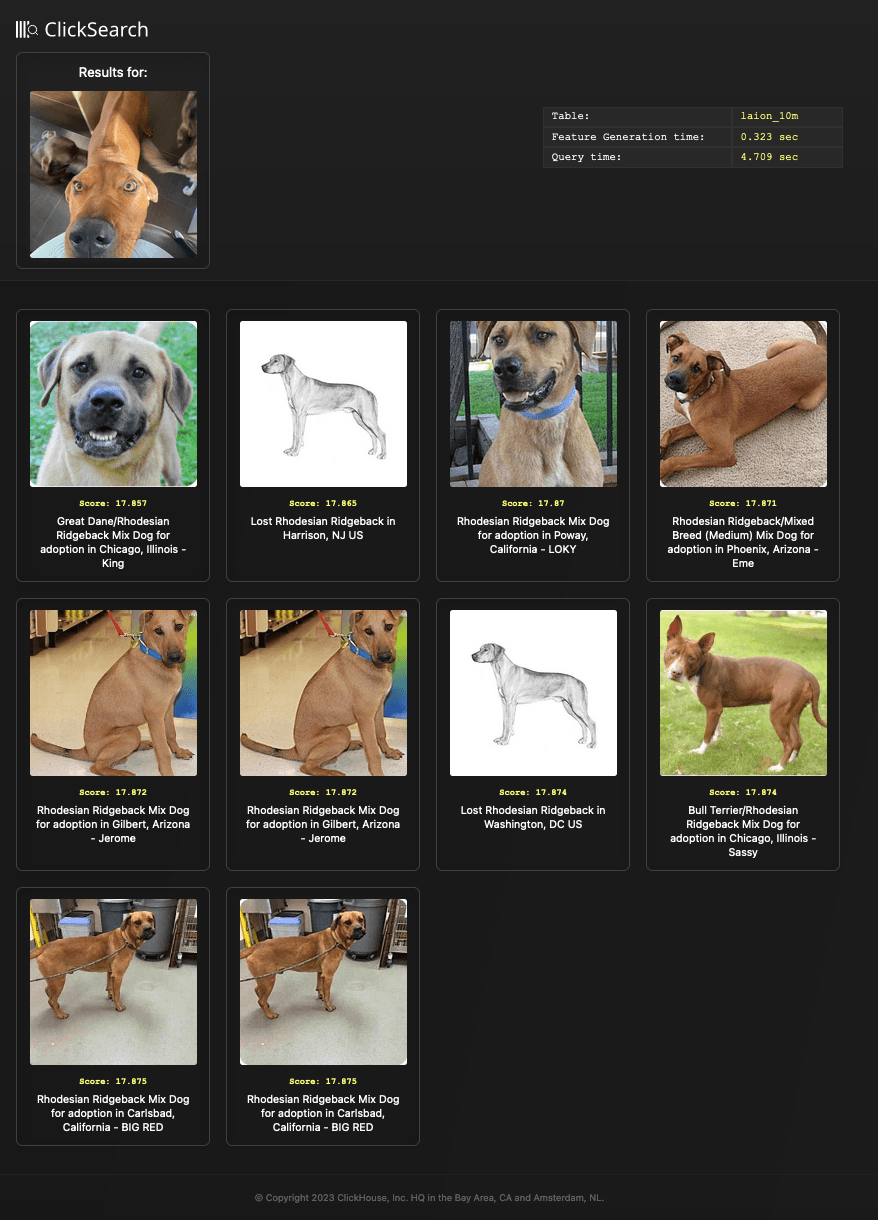
In both of these examples, we have matched embeddings for different modals, i.e. embeddings from image inputs are matched against the text_embedding column and vice versa. This aligns with the original model training as described earlier, and is the intended application. While matching input embeddings against the same type has been explored, previous attempts have resulted in mixed results.
The benefits of SQL
Oftentimes, in practice with vector search, we don’t just search across embeddings. Frequently, there is additional utility in combining search with filtering or aggregating on metadata.
Filtering with metadata
As an example, suppose we wish to perform vector search on images that are non-copyrighted. This kind of query would combine vector search with filtering based on copyright metadata.
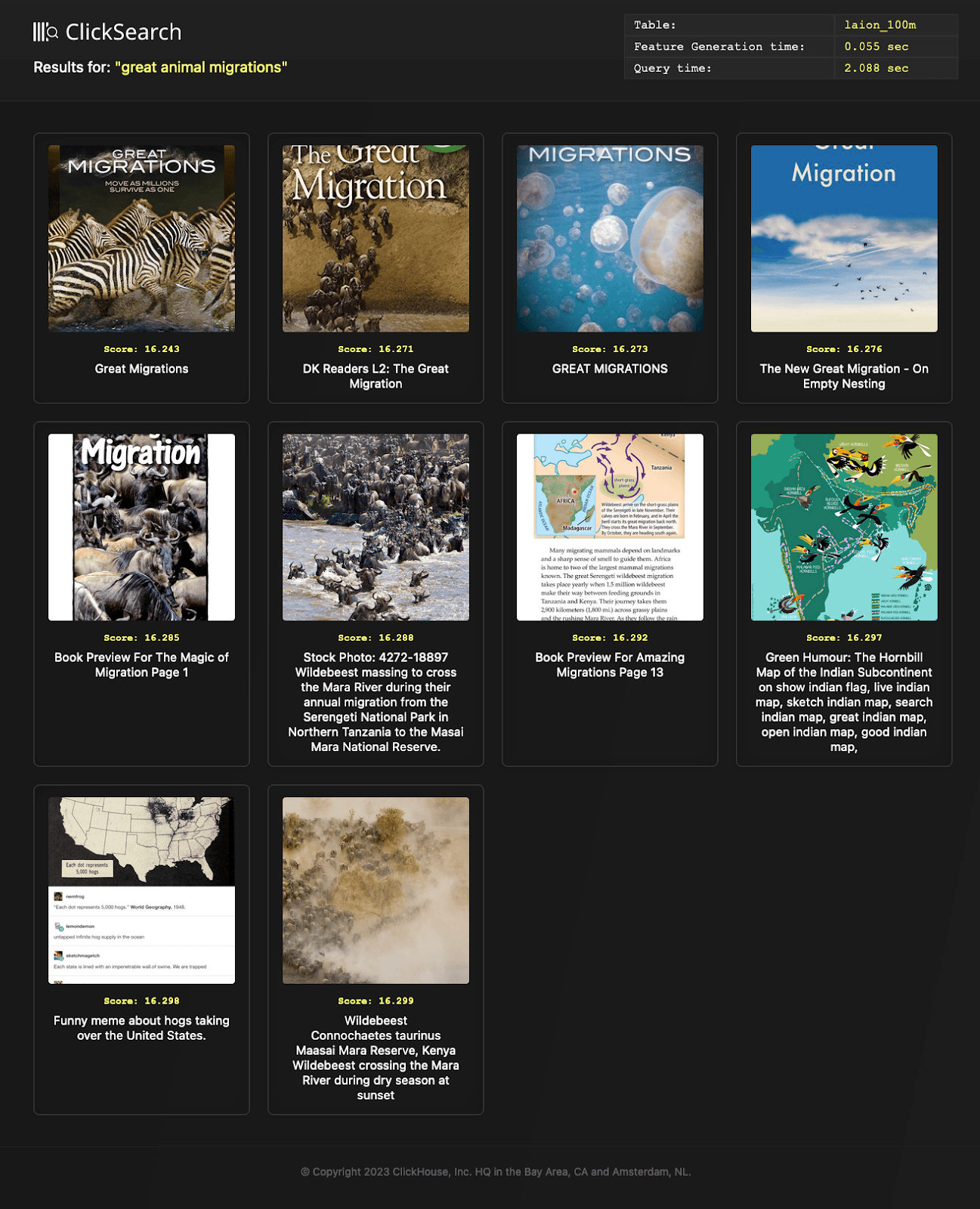
To take another example, suppose we want to limit our search to large images only - at least 300px*500px, and where the caption similarity satisfies a higher cosine similarity score of 0.3. For this example, let’s start with a search for “great animal migrations.” Fortunately, formulating this as a SQL query is simple. Below, we execute this query for 100 million images.
SELECT
url,
caption,
L2Distance(image_embedding, [<embedding>]) AS score
FROM laion_100m
WHERE (width >= 300) AND (height >= 500) AND (copyright = '') AND similarity > 0.3
ORDER BY score ASC
LIMIT 10
FORMAT Vertical
Row 1:
──────
url: https://aentcdn.azureedge.net/graphics/items/sdimages/a/500/3/6/5/4/1744563.jpg
caption: Great Migrations
width: 366
height: 500
score: 16.242750635008512
Row 2:
──────
url: https://naturefamiliesdotorg.files.wordpress.com/2017/01/on-the-move.jpg?w=418&h=557
caption: on-the-move
width: 384
height: 512
score: 16.26983713529263
10 rows in set. Elapsed: 2.010 sec. Processed 6.82 million rows, 22.52 GB (3.39 million rows/s., 11.20 GB/s.)
This illustrates the benefits of using SQL and metadata to limit your vector comparisons to a subset. In this specific case, we query over 100 million vectors, but reduce the actual distance matching to fewer than 7 million because of our metadata.
For convenience, we’ve also added the ability to pass an additional filter to our search.py, allowing us to verify the quality of the above matches:
python search.py search --filter "(width >= 300) AND (height >= 500) AND (copyright = '') AND simularity > 0.3" --text "great animal migrations"
Aggregating with metadata
In addition to filtering, we can also perform aggregations on the metadata. As a column-oriented database, ClickHouse is well suited to this task.
Suppose, for instance, we wanted to identify the primary camera models used for ‘safari pictures.’ We perform that search here:
WITH results AS
(
SELECT
image_make,
image_model,
L2Distance(image_embedding, [<embedding>]) AS score
FROM laion_100m
WHERE (image_make != '') AND (image_model != '')
ORDER BY score ASC
LIMIT 1000
)
SELECT
image_make,
image_model,
count() AS c
FROM results
GROUP BY
image_make,
image_model
ORDER BY c DESC
LIMIT 10
┌─image_make────────┬─image_model───────────┬──c─┐
│ Canon │ Canon EOS 7D │ 64 │
│ Canon │ Canon EOS-1D X │ 51 │
│ Canon │ Canon EOS 5D Mark III │ 49 │
│ NIKON CORPORATION │ NIKON D700 │ 26 │
│ NIKON CORPORATION │ NIKON D800 │ 24 │
│ Canon │ Canon EOS 5D Mark II │ 23 │
│ NIKON CORPORATION │ NIKON D810 │ 23 │
│ NIKON CORPORATION │ NIKON D7000 │ 21 │
│ Canon │ Canon EOS 40D │ 18 │
│ Canon │ Canon EOS 60D │ 17 │
└───────────────────┴───────────────────────┴────┘
10 rows in set. Elapsed: 23.897 sec. Processed 100.00 million rows, 286.70 GB (4.18 million rows/s., 12.00 GB/s.)
Clearly, Canon should be your camera of choice for your next safari. Note that here, we only use the top 1000 results. Unlike cosine distance, which is unbounded, euclidean distance has no upper limit - making imposing a threshold challenging.
Using inverted indices
Note: Inverted indices are an experimental feature in ClickHouse.
ClickHouse’s experimental secondary indices feature can also prove to be useful with vector handling.
For instance, we may wish to enforce a filter that limits our safari pictures to those containing lions. To do so, we could impose a token restriction - requiring the caption column to contain the string lions.
Without inverted indices, our search might look something like the following. Here, we utilize the embedding for the following picture and search against 100M vectors.

SELECT url, caption, L2Distance(text_embedding, [<embedding>]) AS score FROM laion_10m WHERE SELECT
url,
caption,
L2Distance(text_embedding, [-0.17659325897693634, …, 0.05511629953980446]) AS score
FROM laion_100m
WHERE hasToken(lower(caption), 'lions')
ORDER BY score ASC
LIMIT 10
FORMAT Vertical
Row 1:
──────
url: https://static.wixstatic.com/media/c571fa_25ec3694e6e04a39a395d07d63ae58fc~mv2.jpg/v1/fill/w_420,h_280,al_c,q_80,usm_0.66_1.00_0.01/Mont%20Blanc.jpg
caption: Travel on a safari to Tanzania, to the rolling plains of the Serengeti, the wildlife-filled caldera of the Ngorongoro Crater and the lions and baobabs of Tarangire; Tanzania will impress you like few other countries will. This tailor-made luxury safari will take you to three very different parks in northern Tanzania, each with their own scenery and resident wildlife. As with all our private tours, this sample itinerary can be completely tailored to create the perfect journey of discovery for you.
score: 18.960329963316692
Row 2:
──────
url: https://thumbs.dreamstime.com/t/jeepsafari-ngorongoro-tourists-photographers-watching-wild-lions-who-walk-jeeps-79635001.jpg
caption: Jeep safari in Ngorongoro3. Tourists and photographers are watching wild lions, who walk between the jeeps Stock Image
score: 18.988379350742093
hasToken(lower(caption), 'lions') ORDER BY score ASC LIMIT 10 FORMAT Vertical
10 rows in set. Elapsed: 6.194 sec. Processed 93.82 million rows, 79.00 GB (15.15 million rows/s., 12.75 GB/s.)
To accelerate this kind of metadata query, we can exploit inverted indices, and add an inverted index for the caption column.
SET allow_experimental_inverted_index=1
ALTER TABLE laion_100m ADD INDEX caption_idx(lower(caption)) TYPE inverted;
ALTER TABLE laion_100m MATERIALIZE INDEX caption_idx;
Repeating our previous query, we can see this delivers significant improvement in query time. The inverted index can be used to limit the number of rows for our distance comparison to 30 million, reducing the time from 6 secs to 3 secs.
SELECT url, caption, L2Distance(text_embedding, [<embedding>]) AS score FROM laion_10m WHERE SELECT
url,
caption,
L2Distance(text_embedding, [-0.17659325897693634, ..., 0.05511629953980446]) AS score
FROM laion_100m
WHERE hasToken(lower(caption), 'lions')
ORDER BY score ASC
LIMIT 10
FORMAT Vertical
Row 1:
──────
url: https://static.wixstatic.com/media/c571fa_25ec3694e6e04a39a395d07d63ae58fc~mv2.jpg/v1/fill/w_420,h_280,al_c,q_80,usm_0.66_1.00_0.01/Mont%20Blanc.jpg
caption: Travel on a safari to Tanzania, to the rolling plains of the Serengeti, the wildlife-filled caldera of the Ngorongoro Crater and the lions and baobabs of Tarangire; Tanzania will impress you like few other countries will. This tailor-made luxury safari will take you to three very different parks in northern Tanzania, each with their own scenery and resident wildlife. As with all our private tours, this sample itinerary can be completely tailored to create the perfect journey of discovery for you.
score: 18.960329963316692
Row 2:
──────
url: https://thumbs.dreamstime.com/t/jeepsafari-ngorongoro-tourists-photographers-watching-wild-lions-who-walk-jeeps-79635001.jpg
caption: Jeep safari in Ngorongoro3. Tourists and photographers are watching wild lions, who walk between the jeeps Stock Image
score: 18.988379350742093
10 rows in set. Elapsed: 3.554 sec. Processed 32.96 million rows, 74.11 GB (9.27 million rows/s., 20.85 GB/s.)
The results of this query are as follows:
python search.py search --image ./images/safari.jpg --table laion_100m --filter "hasToken(lower(caption), 'lions')"

Advanced features
Approximate Nearest Neighbour (Annoy)
Note: Annoy indexes are highly experimental in ClickHouse.
An Annoy index is designed to improve the efficiency of large-scale nearest-neighbor vector searches. With it comes a trade-off between accuracy and computational efficiency.
Specifically, an Annoy index is a data structure used for finding approximate nearest neighbors in high-dimensional spaces. Annoy works by organizing vectors into a tree structure. It divides the high-dimensional space into partitions using random hyperplanes (lines in 2d space, planes in 3d, etc.). These hyperplanes split the space into smaller regions, with each region containing only a subset of the data points. These partitions are, in turn, used to build a tree structure (typically binary), where each node represents a hyperplane, and the child nodes represent the regions that split the plane. The leaf nodes of the tree contain the actual data points. Balancing and optimization techniques, such as randomizing the insertion and using heuristics to determine the best hyperplanes for partitioning, ensure that the tree is efficient and well-balanced.
Once an Annoy index is constructed, it can be used for search. On providing a vector, the tree can be traversed by comparing each vector to each internal node's hyperplanes. At each level of the tree, Annoy estimates the distance between the query vector and the regions represented by the child nodes. Distance measures determine which child node to explore further. Upon reaching either the root or a specified node, the set of nodes it has encountered is returned. The result is an approximate set of results with potentially much faster search times than a linear scan.
 Image of hyperplanes split by Annoy
Image of hyperplanes split by Annoy
When creating the Annoy index for ClickHouse, we can specify both a NumTree and a DistanceName. The latter represents the distance function used, which defaults to L2Distance and is appropriate for our LAION dataset. The former represents the number of trees that the algorithm will create. The bigger the tree is, the slower it works (in both CREATE and SELECT requests), but the better accuracy you get (adjusted for randomness). By default, NumTree is set to 100.
Below, we show the schema for the LAION dataset with an Annoy index for each embedding field. We utilize defaults for the index and populate the table with 100m rows.
SET allow_experimental_annoy_index = 1
CREATE TABLE default.laion_100m_annoy
(
`_file` LowCardinality(String),
`key` String,
`url` String,
`caption` String,
`similarity` Float64,
`width` Int64,
`height` Int64,
`original_width` Int64,
`original_height` Int64,
`status` LowCardinality(String),
`NSFW` LowCardinality(String),
`exif` Map(String, String),
`text_embedding` Array(Float32),
`image_embedding` Array(Float32),
`orientation` String DEFAULT exif['Image Orientation'],
`software` String DEFAULT exif['Image Software'],
`copyright` String DEFAULT exif['Image Copyright'],
`image_make` String DEFAULT exif['Image Make'],
`image_model` String DEFAULT exif['Image Model'],
INDEX annoy_image image_embedding TYPE annoy(1000) GRANULARITY 1000,
INDEX annoy_text text_embedding TYPE annoy(1000) GRANULARITY 1000
)
ENGINE = MergeTree
ORDER BY (height, width, similarity)
INSERT INTO laion_100m_annoy SELECT * FROM laion_100m
0 rows in set. Elapsed: 1596.941 sec. Processed 100.00 million rows, 663.68 GB (62.62 thousand rows/s., 415.59 MB/s.)
As shown, the overhead of the Annoy index is significant at insert time with the above insert taking around 27 mins for 100m rows. This compares to 10 mins for a table without these indexes. Below, we repeat our earlier query which took approximately 24 secs (hot).
SELECT
url,
caption,
L2Distance(image_embedding, [embedding]) AS score
FROM laion_100m_annoy
ORDER BY score ASC
LIMIT 10 FORMAT Vertical
Row 1:
──────
url: https://i.dailymail.co.uk/i/pix/2012/04/26/article-2135380-12C5ADBC000005DC-90_634x213.jpg
caption: Pampered pets: This hammock-style dog bed offers equal levels of pet comfort
score: 12.313203570174357
Row 2:
──────
url: https://i.pinimg.com/originals/15/c2/11/15c2118a862fcd0c4f9f6c960d2638a0.jpg
caption: rhodesian ridgeback lab mix puppy
score: 12.333195649580162
10 rows in set. Elapsed: 1.456 sec. Processed 115.88 thousand rows, 379.06 MB (79.56 thousand rows/s., 260.27 MB/s.)
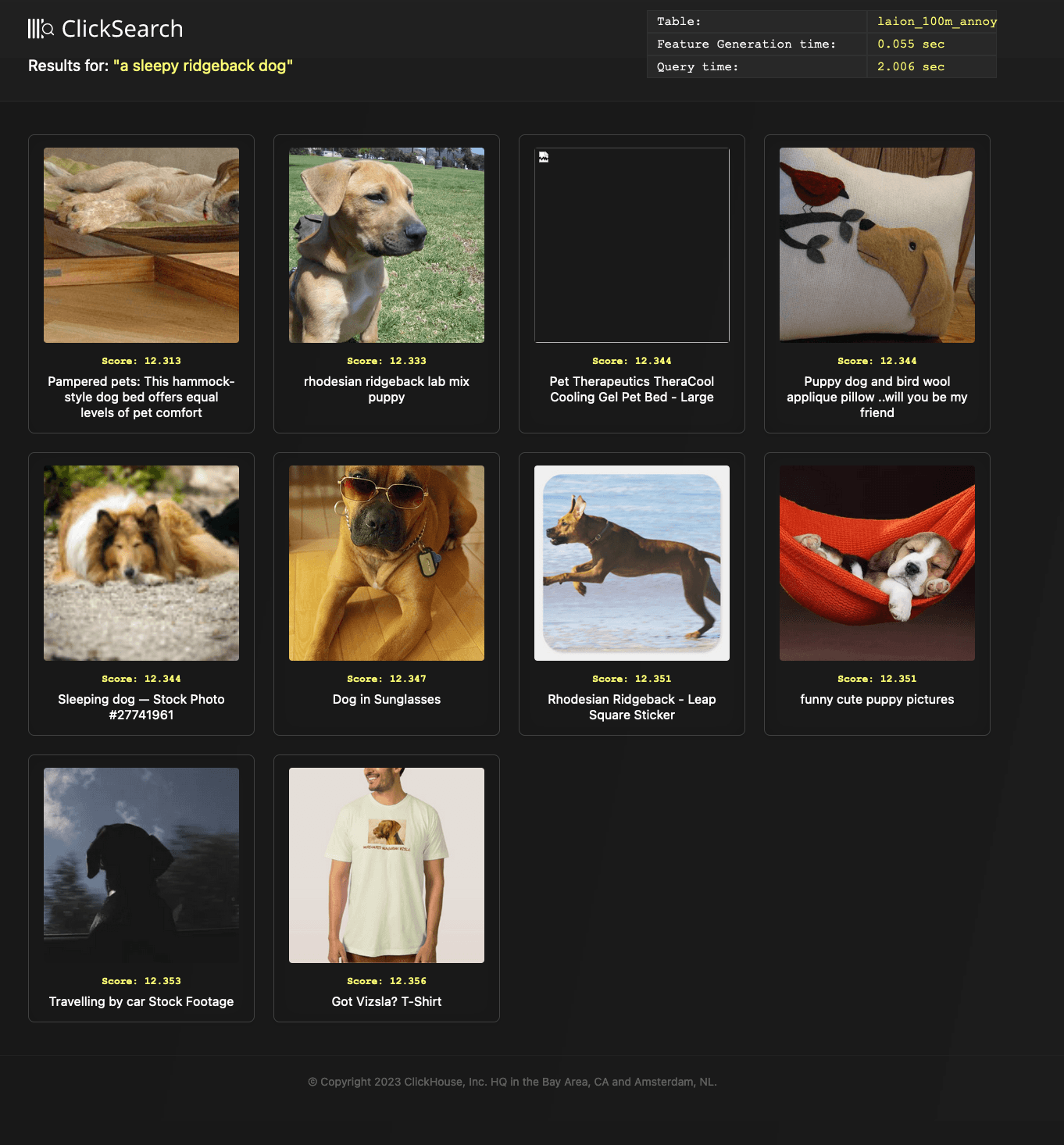
The Annoy index delivers a significant improvement with respect to query performance, with this query taking between 1 and 2s, at the expense of some search quality.
The test embedding here represents our "a sleepy ridgeback dog" text. We can see the image results below.
python search.py search --text "a sleepy ridgeback dog" --table laion_100m_annoy
In ClickHouse, it’s important to note that the Annoy index can be used to speed up queries that either leverage an ORDER BY DistanceFunction(Column, vector) or a WHERE DistanceFunction(Column, Point) < MaxDistance, but not both. A LIMIT must be imposed on the query, to return the top N matches. To return the top matches a priority queue-based buffer is used for collecting the matching vectors. Once full, the collection stops, and the buffer is sorted. The size of this buffer is limited by the setting max_limit_for_ann_queries (1000000 by default).
User Defined Functions (UDFs)
ClickHouse’s user-defined functions, or UDFs, allow users to extend the behavior of ClickHouse by creating lambda expressions that can leverage SQL constructs and functions. These functions can then be used like any in-built function in a query.
Up to now, we've relied on performing our vector generation outside of ClickHouse, and passing the generated embedding at query time from our search.py script. While this is sufficient, it would be nice if we could instead simply pass text or image paths (or even urls!) in the SQL query directly.
We can use UDFs to accomplish this task. The UDFs defined below are called embedText and embedImage, respectively.
SELECT
url,
caption,
L2Distance(image_embedding, embedText('a sleepy ridgeback dog')) AS score
FROM laion_10m
ORDER BY score ASC
LIMIT 10
SELECT
url,
caption,
L2Distance(text_embedding, embedImage("https://dogpictures.com/ridgeback.jpg")) as score
FROM laion_100m
ORDER BY score ASC
LIMIT 10
In order to define the embedText UDF, we start by adapting our earlier generate.py, used to generate the embeddings, to embed_text.py below.
Note: This should be saved in the user_scripts folder of ClickHouse.
#!/usr/bin/python3
import clip
import torch
import sys
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-L/14", device=device)
if __name__ == '__main__':
for text in sys.stdin:
inputs = clip.tokenize(text)
with torch.no_grad():
text_features = []
text_features = model.encode_text(inputs)[0].tolist()
print(text_features)
sys.stdout.flush()
This embed_text.py script can then be exposed through the custom function, embedText. The following configuration can be placed under the ClickHouse configuration directory (default /etc/clickhouse-server/) with the name embed_text__function.xml.
Note: Users should ensure the dependencies for this script have been installed for the clickhouse user - see here for steps.
<functions>
<function>
<type>executable</type>
<name>embedText</name>
<return_type>Array(Float32)</return_type>
<argument>
<type>String</type>
<name>text</name>
</argument>
<format>TabSeparated</format>
<command>embed_text.py</command>
<command_read_timeout>1000000</command_read_timeout>
</function>
</functions>
With the function registered, we can now utilize this as shown in our previous example:
SELECT
url,
caption,
L2Distance(image_embedding, embedText('a sleepy ridgeback dog')) AS score
FROM laion_10m
ORDER BY score ASC
LIMIT 10
For our similar embedImage function, we add another UDF based on the following python script embed_image.py.
#!/usr/bin/python3
from io import BytesIO
from PIL import Image
import requests
import clip
import torch
import sys
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-L/14", device=device)
if __name__ == '__main__':
for url in sys.stdin:
response = requests.get(url.strip())
response.raise_for_status()
image = preprocess(Image.open(BytesIO(response.content))).unsqueeze(0).to(device)
with torch.no_grad():
print(model.encode_image(image)[0].tolist())
sys.stdout.flush()
<functions>
<function>
<type>executable_pool</type>
<name>embedImage</name>
<return_type>Array(Float32)</return_type>
<argument>
<type>String</type>
</argument>
<format>TabSeparated</format>
<command>embed_image.py</command>
<command_read_timeout>1000000</command_read_timeout>
</function>
</functions>
When the UDF is set to type executable_pool, ClickHouse maintains a pool of pre-loaded python instances ready to receive input. For our function, this is beneficial as it reduces model load time after the first execution. This allows subsequent invocations to be much faster. For further details on how the pool size can be controlled and other configuration parameters, further details can be found here.
Now that both UDFs are configured, we can query as follows:
SELECT embedImage('https://cdn.britannica.com/12/236912-050-B39F82AF/Rhodesian-Ridgeback-dog.jpg')
...
1 row in set. Elapsed: 13.421 sec.
SELECT embedImage('https://cdn.britannica.com/12/236912-050-B39F82AF/Rhodesian-Ridgeback-dog.jpg')
...
1 row in set. Elapsed: 0.317 sec.
SELECT
url,
caption,
L2Distance(image_embedding, embedImage('https://cdn.britannica.com/12/236912-050-B39F82AF/Rhodesian-Ridgeback-dog.jpg')) AS score
FROM laion_10m
ORDER BY score ASC
LIMIT 10
Completing this, we can expose our earlier concept math capabilities with an embed_concept.py script and function embedConcept.
select embedConcept('(berlin - germany) + (uk + bridge)')
SELECT
url,
caption,
L2Distance(image_embedding, embedConcept('(berlin - germany) + (uk + bridge)')) AS score
FROM laion_10m
ORDER BY score ASC
LIMIT 10
Note that the examples above do not include error handling and input validation. We leave this as an exercise for the reader. Hopefully these examples have provided some inspiration for combining User Defined Functions, embedding models, and vector search!
Improving compression
Enhanced compression techniques may help with overall data size and storage needs. For instance, our previous schema and resulting compression statistics were based on storing our vectors as the type Array(Float32). Though, for some models, 32-bit floating point precision is not required, and similar matching quality can be achieved by reducing this to 16 bits.
While ClickHouse does not have a native 16-bit floating point type, we can still reduce our precision to 16 bits and reuse the Float32 type, with each value simply padded with zeros. These zeros will be efficiently compressed with the ZSTD codec (the standard in ClickHouse Cloud), reducing our compressed storage requirements.
To achieve this, we need to ensure that the encoding of the 16-bit floating point values is done properly. Fortunately, Google's bloat16 type for Machine Learning use cases works well, and simply requires truncating the last 16 bits of a 32-bit floating point number, assuming the latter uses the IEE-754 encoding.
 Credit: https://cloud.google.com/tpu/docs/bfloat16
Credit: https://cloud.google.com/tpu/docs/bfloat16
While bfloat16 is not currently native to ClickHouse, it can easily be replicated with other functions. We do so below for the image_embedding and text_embedding columns.
To do so, all rows from the table laion_100m (containing 100m rows) are selected, and inserted into the table laion_100m_bfloat16 using an INSERT INTO SELECT clause. During the SELECT, we transform the values in the embeddings to a BFloat16 representation.
This bfloat16 conversion is achieved using an arrayMap function, i.e., arrayMap(x -> reinterpretAsFloat32(bitAnd(reinterpretAsUInt32(x), 4294901760)), image_embedding).
This iterates over every value x in a vector embedding, executing the transformation reinterpretAsFloat32(bitAnd(reinterpretAsUInt32(x), 4294901760)) - this interprets the binary sequence as an Int32 using the function reinterpretAsUInt32 and performs a bitAnd with the value 4294901760. This latter value is the binary sequence 000000000000000001111111111111111. This operation, therefore, zeros the trailing 16 bits, performing an effective truncation. The resulting binary value is then re-interpreted as a float32.
We illustrate this process below:
INSERT INTO default.laion_1m_bfloat16 SELECT
_file,
key,
url,
caption,
similarity,
width,
height,
original_width,
original_height,
status,
NSFW,
exif,
arrayMap(x -> reinterpretAsFloat32(bitAnd(reinterpretAsUInt32(x), 4294901760)), text_embedding) AS text_embedding,
arrayMap(x -> reinterpretAsFloat32(bitAnd(reinterpretAsUInt32(x), 4294901760)), image_embedding) AS image_embedding,
orientation,
software,
copyright,
image_make,
image_model
FROM laion_1m

As shown below, this has the effect of reducing our compressed data by over 35% - 0s compress really well.
SELECT
table,
name,
formatReadableSize(sum(data_compressed_bytes)) AS compressed_size,
formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed_size,
round(sum(data_uncompressed_bytes) / sum(data_compressed_bytes), 2) AS ratio
FROM system.columns
WHERE (table IN ('laion_100m', 'laion_100m_bfloat16', 'laion_10m', 'laion_10m_bfloat16')) AND (name IN ('text_embedding', 'image_embedding'))
GROUP BY
table,
name
ORDER BY table DESC
┌─table───────────────┬─name────────────┬─compressed_size─┬─uncompressed_size─┬─ratio─┐
│ laion_10m_bfloat16 │ text_embedding │ 13.51 GiB │ 28.46 GiB │ 2.11 │
│ laion_10m_bfloat16 │ image_embedding │ 13.47 GiB │ 28.46 GiB │ 2.11 │
│ laion_10m │ text_embedding │ 18.36 GiB │ 28.59 GiB │ 1.56 │
│ laion_10m │ image_embedding │ 18.36 GiB │ 28.59 GiB │ 1.56 │
│ laion_100m_bfloat16 │ image_embedding │ 134.02 GiB │ 286.75 GiB │ 2.14 │
│ laion_100m_bfloat16 │ text_embedding │ 134.82 GiB │ 286.75 GiB │ 2.13 │
│ laion_100m │ text_embedding │ 181.64 GiB │ 286.43 GiB │ 1.58 │
│ laion_100m │ image_embedding │ 182.29 GiB │ 286.43 GiB │ 1.57 │
└─────────────────────┴─────────────────┴─────────────────┴───────────────────┴───────┘
8 rows in set. Elapsed: 0.009 sec.
With our precision reduced to 16 bits, further increases in the ZSTD compression level will have less impact than for our 32 bit representation. As shown below, ZSTD(3) makes a minimal difference to our compressed bfloat16.
SELECT
table,
name,
formatReadableSize(sum(data_compressed_bytes)) AS compressed_size,
formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed_size,
round(sum(data_uncompressed_bytes) / sum(data_compressed_bytes), 2) AS ratio
FROM system.columns
WHERE (table IN ('laion_100m_bfloat16', 'laion_100m_bfloat16_zstd_3')) AND (name IN ('text_embedding', 'image_embedding'))
GROUP BY
table,
name
ORDER BY table DESC
┌─table──────────────────────┬─name────────────┬─compressed_size─┬─uncompressed_size─┬─ratio─┐
│ laion_100m_bfloat16_zstd_3 │ text_embedding │ 128.12 GiB │ 286.85 GiB │ 2.24 │
│ laion_100m_bfloat16_zstd_3 │ image_embedding │ 127.28 GiB │ 286.85 GiB │ 2.25 │
│ laion_100m_bfloat16 │ image_embedding │ 133.80 GiB │ 286.75 GiB │ 2.14 │
│ laion_100m_bfloat16 │ text_embedding │ 134.59 GiB │ 286.75 GiB │ 2.13 │
└────────────────────────────┴─────────────────┴─────────────────┴───────────────────┴───────┘
This increase in compression has other potential benefits aside from reducing disk space. We demonstrate these benefits through the query performance for tables containing 10m and 100m rows, using both embeddings encoded as float32 and bfloat16. These results are based on the same query used earlier.
| Table | Encoding | Cold (secs) | Hot (secs) |
|---|---|---|---|
| laion_10m | Float32 | 12.851s | 2.406s |
| laion_10m | bloat16 | 7.285s | 1.554s |
| laion_100m | Float32 | 111.857s | 24.444s |
| laion_100m | bloat16 | 71.362s | 16.271s |
The gains on our linear scan speed here are appreciable, with the bfloat16 variant improving our performance from 111 secs to 71 specs for the 100m row dataset on cold queries.
An obvious question might be how this reduction in precision impacts our ability to represent concepts in our vectors and whether it results in reduced search quality. We have, after all, reduced the information encoded in our multidimensional space and effectively condensed our vectors "closer" together. Below we show the results for the earlier "a sleepy ridgeback dog" query using our new laion_100m_v2 table and our search.py script.
python search.py search --text "a sleepy ridgeback dog" --table laion_100m_bfloat16
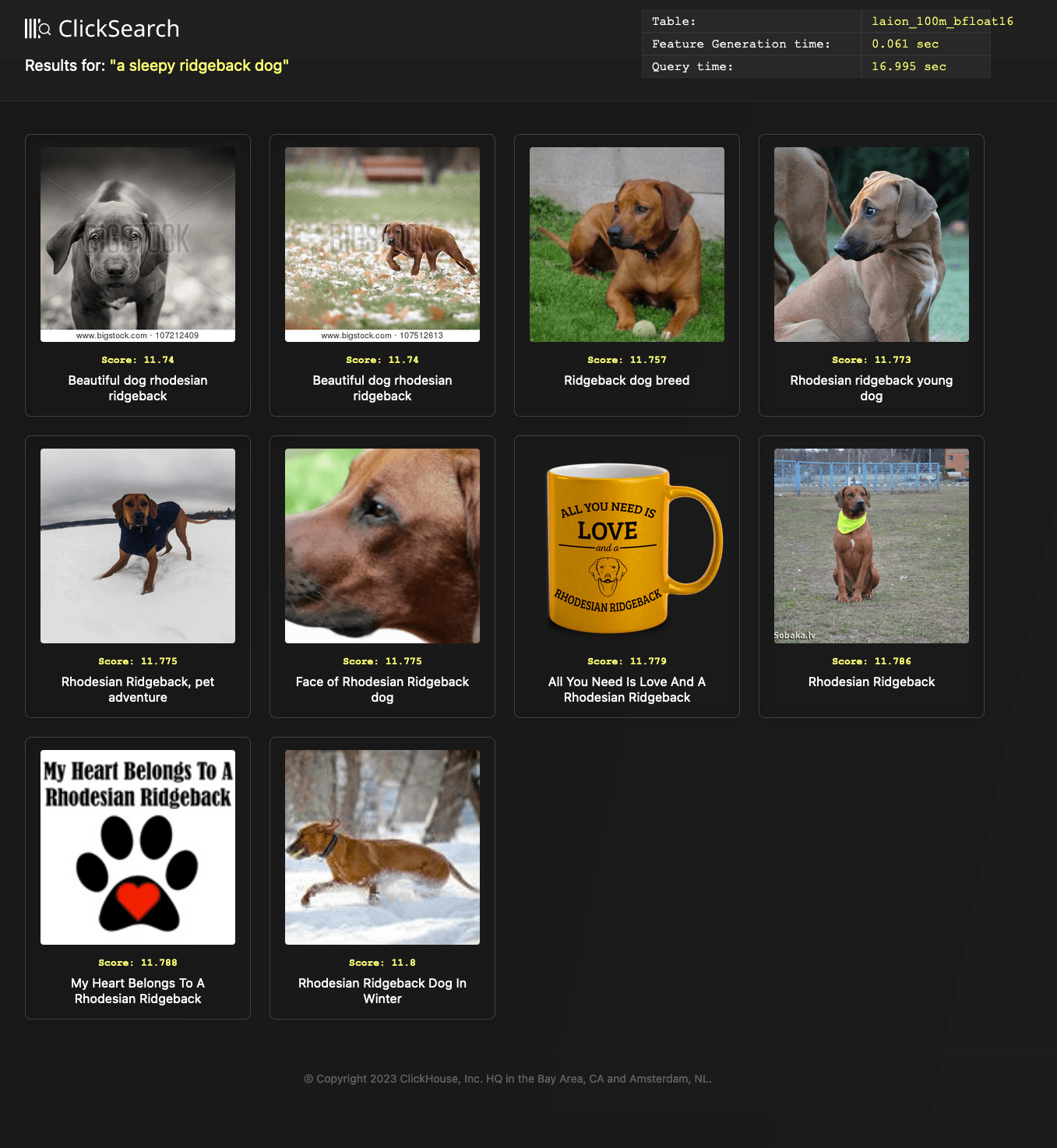
While this is no obvious reduction in search quality for this search, this likely requires relevancy testing across a wider sample of queries. Users will need to test this precision reduction technique on their specific model and dataset, with results likely varying case by case.
Bonus vector fun
After reading an interesting blog post about how vector math can be used to move around a high-dimensionality space, we thought it might be interesting to see if the same concepts could be applied to our CLIP-generated embeddings.
For example, suppose we have embeddings for the words Berlin, Germany, United Kingdom, and Bridge. The following mathematical operation can be performed on their respective vectors.
(berlin - germany) + ('united kingdom' + bridge)
If we logically subtract and add the above concepts, we could hypothesize that the result would represent a bridge in London.
Testing this idea, we enhanced our simple search.py script to support a basic parser that could accept input similar to the above. This parser supports the operations +, -, * and /, as well as ' to denote multi-term input, and is exposed through a concept_math command.
Thanks to the great pyparsing library, building a parser for this grammar is trivial. In summary, the above phrase would be parsed into the following syntax tree:
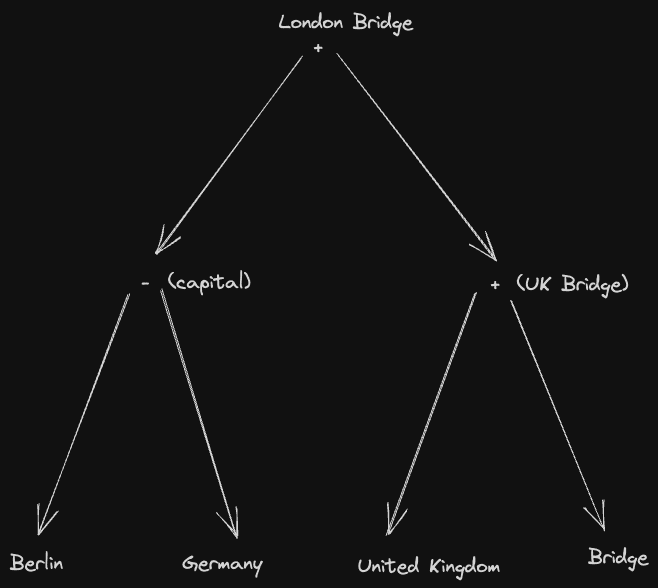
We can, in turn, recursively compute the vectors for the text terms (the leafs) in the above tree. Branches can then be combined using the equivalent vector functions in ClickHouse for the specified mathematical operator. This process is performed depth-first, resolving the entire tree to a single query (which should represent the equivalent concept).
Finally, this function is matched on the image_embedding column using the same process as a standard search. The above would therefore resolve to the follow query:
SELECT url, caption,
L2Distance(image_embedding,
arrayMap((x,y) -> x+y,
arrayMap((x,y) -> x-y, [berlin embedding], [germany embedding]),
arrayMap((x,y) -> x+y, ['united kingdom' embedding], [bridge embedding])
)
) AS score FROM laion_10m ORDER BY score ASC LIMIT 10
Notice that we use the arrayMap function to push down our pointwise addition and subtraction (support for + and - operators as pointwise operations is under consideration).
We show the results for this below, matching on the 10m row sample:
python search.py concept_math —-text "(berlin - germany) + ('united kingdom' + bridge)"
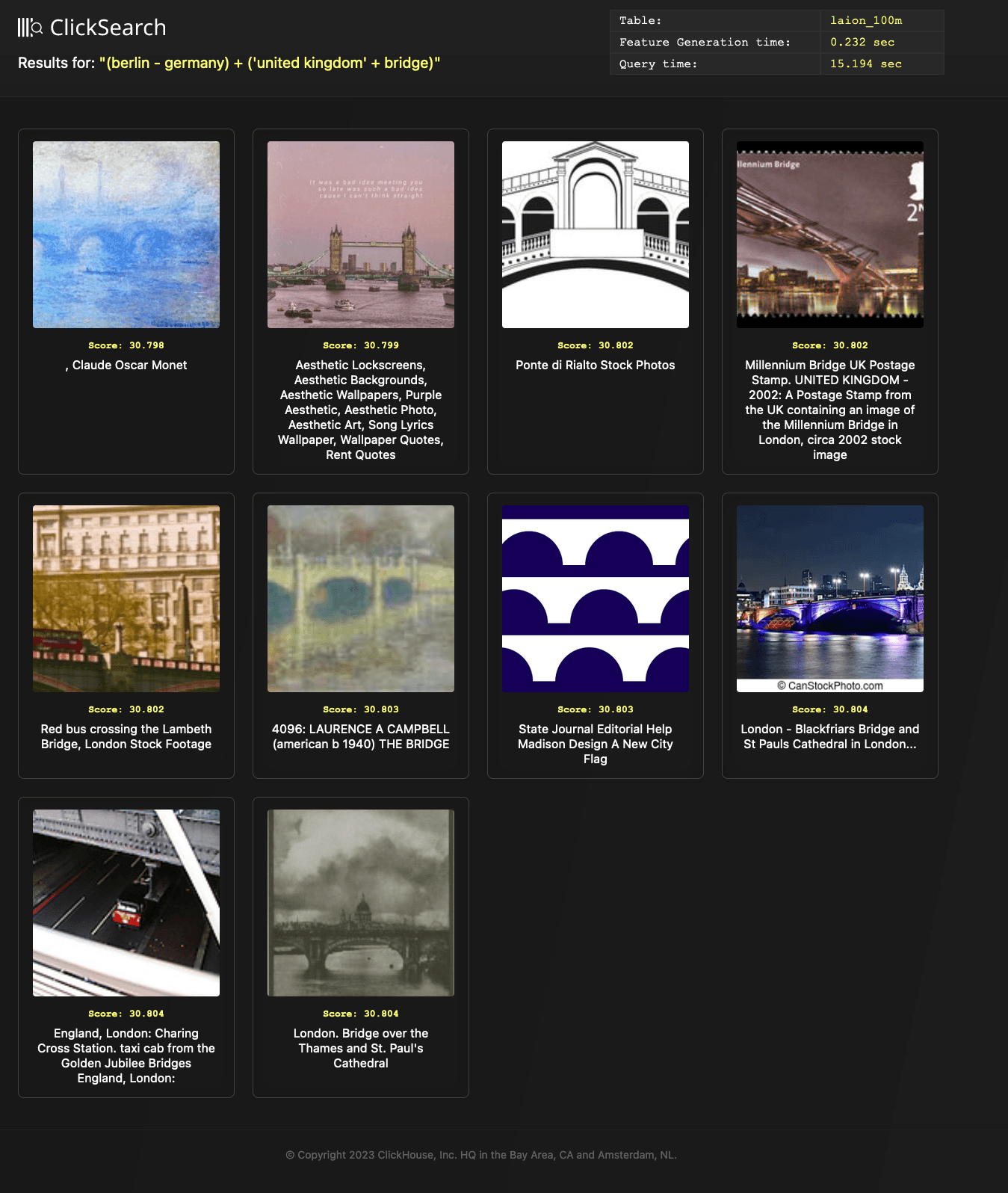
Cool! It works! Notice how the text has no mention of London Bridge - the first image is part of Claude Monet Waterloo Bridge series of paintings.
Finally, we thought enhancing the grammar parser to support integer constants could be useful. Specifically, we wanted to see whether the midpoint between two contrasting concepts produced something interesting. For example, what might the art between the concepts cubism and surrealism represent? This can be mathematically represented as (cubism+surrealism)/2. Executing this search actually produced something interesting:
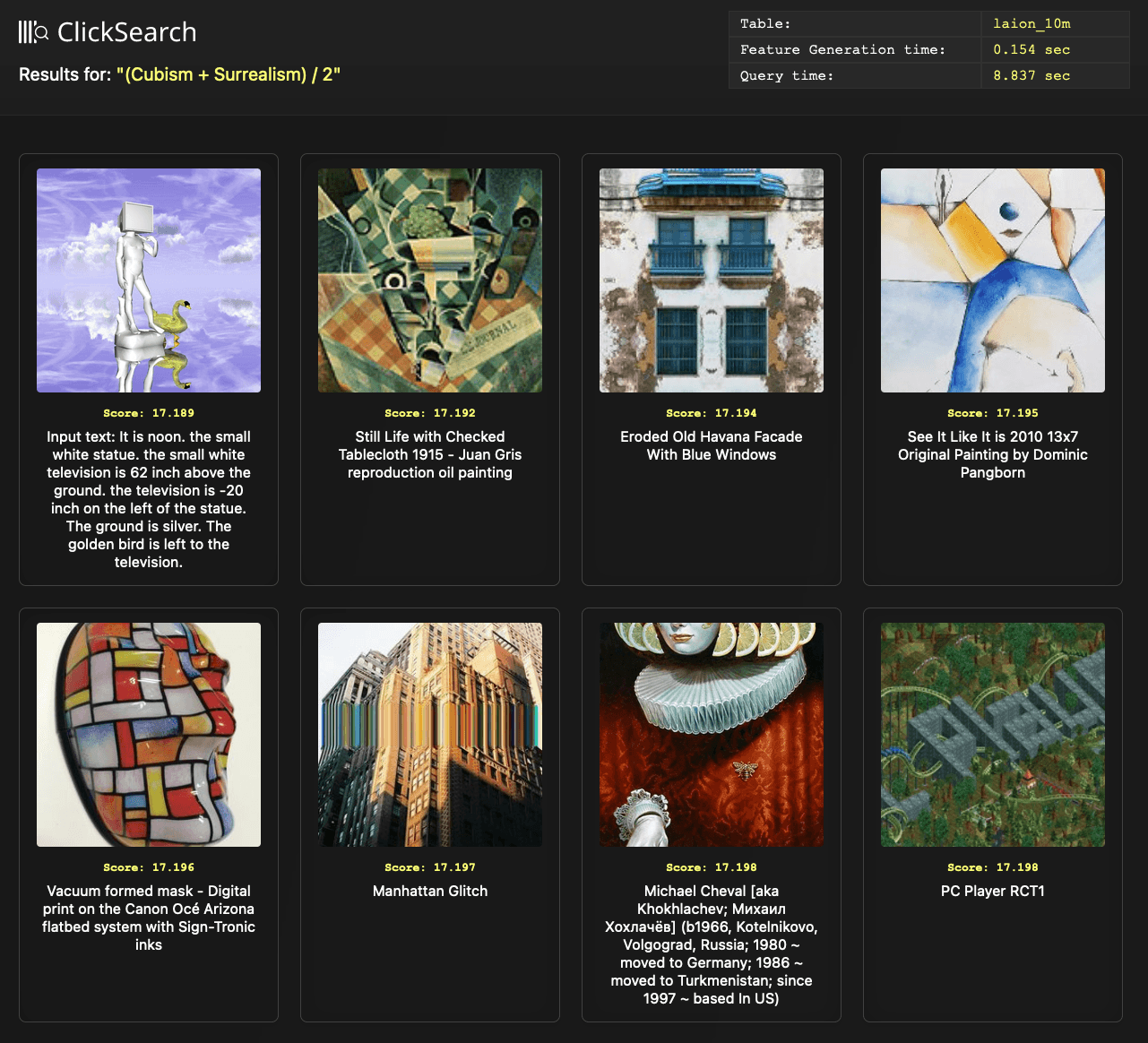
We leave it to the artists in our readership to comment on the relevance and accuracy here.
This demonstrates yet another interesting possibility for combining vectors. There are no doubt other cases where this basic vector math can be useful. We'd love to hear about any examples!
Conclusion
In this blog post, we’ve shown how a vector dataset of 2 billion rows can be converted into Parquet format and loaded into ClickHouse. We have demonstrated that this compresses well, and that linear search can be scaled with CPUs and complemented with full SQL-based analytics using metadata. Finally, we have shown some newer ANN features of ClickHouse and explored how UDFs can be used to provide elegant functions for generating embeddings.
Get started with ClickHouse Cloud today and receive $300 in credits. At the end of your 30-day trial, continue with a pay-as-you-go plan, or contact us to learn more about our volume-based discounts. Visit our pricing page for details.
Share this post
Subscribe to our newsletter
Stay informed on feature releases, product roadmap, support, and cloud offerings!
Loading form...



{kind=link}
{kind=link}
Follow us
Products
Comparisons
Stay informed on feature releases, product roadmap, support, and cloud offerings!
Loading form...
© 2025 ClickHouse, Inc. HQ in the Bay Area, CA and Amsterdam, NL.