Using ClickHouse for Observability
Introduction
This guide is designed for users looking to build their own SQL-based Observability solution using ClickHouse, focusing on logs and traces. This covers all aspects of building your own solution including considerations for ingestion, optimizing schemas for your access patterns and extracting structure from unstructured logs.
ClickHouse alone is not an out-of-the-box solution for Observability. It can, however, be used as a highly efficient storage engine for Observability data, capable of unrivaled compression rates and lightning-fast query response times. In order for users to use ClickHouse within an Observability solution, both a user interface and data collection framework are required. We currently recommend using Grafana for visualization of Observability signals and OpenTelemetry for data collection (both are officially supported integrations).

While our recommendation is to use the OpenTelemetry (OTel) project for data collection, similar architectures can be produced using other frameworks and tools e.g. Vector and Fluentd (see an example with Fluent Bit). Alternative visualization tools also exist including Superset and Metabase.
Why use ClickHouse?
The most important feature of any centralized Observability store is its ability to quickly aggregate, analyze, and search through vast amounts of log data from diverse sources. This centralization streamlines troubleshooting, making it easier to pinpoint the root causes of service disruptions.
With users increasingly price-sensitive and finding the cost of these out-of-the-box offerings to be high and unpredictable in comparison to the value they bring, cost-efficient and predictable log storage, where query performance is acceptable, is more valuable than ever.
Due to its performance and cost efficiency, ClickHouse has become the de facto standard for logging and tracing storage engines in observability products.
More specifically, the following means ClickHouse is ideally suited for the storage of observability data:
- Compression - Observability data typically contains fields for which the values are taken from a distinct set e.g. HTTP codes or service names. ClickHouse’s column-oriented storage, where values are stored sorted, means this data compresses extremely well - especially when combined with a range of specialized codecs for time-series data. Unlike other data stores, which require as much storage as the original data size of the data, typically in JSON format, ClickHouse compresses logs and traces on average up to 14x. Beyond providing significant storage savings for large Observability installations, this compression assists in accelerating queries as less data needs to be read from disk.
- Fast Aggregations - Observability solutions typically heavily involve the visualization of data through charts e.g. lines showing error rates or bar charts showing traffic sources. Aggregations, or GROUP BYs, are fundamental to powering these charts which must also be fast and responsive when applying filters in workflows for issue diagnosis. ClickHouse's column-oriented format combined with a vectorized query execution engine is ideal for fast aggregations, with sparse indexing allowing rapid filtering of data in response to users' actions.
- Fast Linear scans - While alternative technologies rely on inverted indices for fast querying of logs, these invariably result in high disk and resource utilization. While ClickHouse provides inverted indices as an additional optional index type, linear scans are highly parallelized and use all of the available cores on a machine (unless configured otherwise). This potentially allows 10s of GB/s per second (compressed) to be scanned for matches with highly optimized text-matching operators.
- Familiarity of SQL - SQL is the ubiquitous language with which all engineers are familiar. With over 50 years of development, it has proven itself as the de facto language for data analytics and remains the 3rd most popular programming language. Observability is just another data problem for which SQL is ideal.
- Analytical functions - ClickHouse extends ANSI SQL with analytical functions designed to make SQL queries simple and easier to write. These are essential for users performing root cause analysis where data needs to be sliced and diced.
- Secondary indices - ClickHouse supports secondary indexes, such as bloom filters, to accelerate specific query profiles. These can be optionally enabled at a column level, giving the user granular control and allowing them to assess the cost-performance benefit.
- Open-source & Open standards - As an open-source database, ClickHouse embraces open standards such as Open Telemetry. The ability to contribute and actively participate in projects is appealing while avoiding the challenges of vendor lock-in.
When should you use ClickHouse for Observability
Using ClickHouse for observability data requires users to embrace SQL-based observability. We recommend this blog post for a history of SQL-based observability, but in summary:
SQL-based observability is for you if:
- You or your team(s) are familiar with SQL (or want to learn it)
- You prefer adhering to open standards like OpenTelemetry to avoid lock-in and achieve extensibility.
- You are willing to run an ecosystem fueled by open-source innovation from collection to storage and visualization.
- You envision some growth to medium or large volumes of observability data under management (or even very large volumes)
- You want to be in control of the TCO (total cost of ownership) and avoid spiraling observability costs.
- You can't or don't want to get stuck with small data retention periods for your observability data just to manage the costs.
SQL-based observability may not be for you if:
- Learning (or generating!) SQL is not appealing to you or your team(s).
- You are looking for a packaged, end-to-end observability experience.
- Your observability data volumes are too small to make any significant difference (e.g. <150 GiB) and are not forecasted to grow.
- Your use case is metrics-heavy and needs PromQL. In that case, you can still use ClickHouse for logs and tracing beside Prometheus for metrics, unifying it at the presentation layer with Grafana.
- You prefer to wait for the ecosystem to mature more and SQL-based observability to get more turnkey.
Logs and traces
The Observability use case has three distinct pillars: Logging, Tracing, and Metrics. Each has distinct data types and access patterns.
We currently recommend ClickHouse for storing two types of observability data:
- Logs - Logs are time-stamped records of events occurring within a system, capturing detailed information about various aspects of software operations. The data in logs is typically unstructured or semi-structured and can include error messages, user activity logs, system changes, and other events. Logs are crucial for troubleshooting, anomaly detection, and understanding the specific events leading up to issues within the system.
54.36.149.41 - - [22/Jan/2019:03:56:14 +0330] "GET
/filter/27|13%20%D9%85%DA%AF%D8%A7%D9%BE%DB%8C%DA%A9%D8%B3%D9%84,27|%DA%A9%D9%85%D8%AA%D8%B1%20%D8%A7%D8%B2%205%20%D9%85%DA%AF%D8%A7%D9%BE%DB%8C%DA%A9%D8%B3%D9%84,p53 HTTP/1.1" 200 30577 "-" "Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com/robot/)" "-"
- Traces - Traces capture the journey of requests as they traverse through different services in a distributed system, detailing the path and performance of these requests. The data in traces is highly structured, consisting of spans and traces that map out each step a request takes, including timing information. Traces provide valuable insights into system performance, helping identify bottlenecks, latency issues, and optimize the efficiency of microservices.
While ClickHouse can be used to store metrics data, this pillar is less mature in ClickHouse with pending support for features such as support for the Prometheus data format and PromQL.
Distributed Tracing
Distributed tracing is a critical feature of Observability. A distributed trace, simply called a trace, maps the journey of a request through a system. The request will originate from an end user or application and proliferate throughout a system, typically resulting in a flow of actions between microservices. By recording this sequence, and allowing the subsequent events to be correlated, it allows an observability user or SRE to be able to diagnose issues in an application flow irrespective of how complex or serverless the architecture is.
Each trace consists of several spans, with the initial span associated with the request known as the root span. This root span captures the entire request from beginning to end. Subsequent spans beneath the root provide detailed insights into the various steps or operations that occur during the request. Without tracing, diagnosing performance issues in a distributed system can be extremely difficult. Tracing eases the process of debugging and comprehending distributed systems by detailing the sequence of events within a request as it moves through the system.
Most observability vendors visualize this information as a waterfall, with relative timing shown using horizontal bars of proportional size. For example, in Grafana:
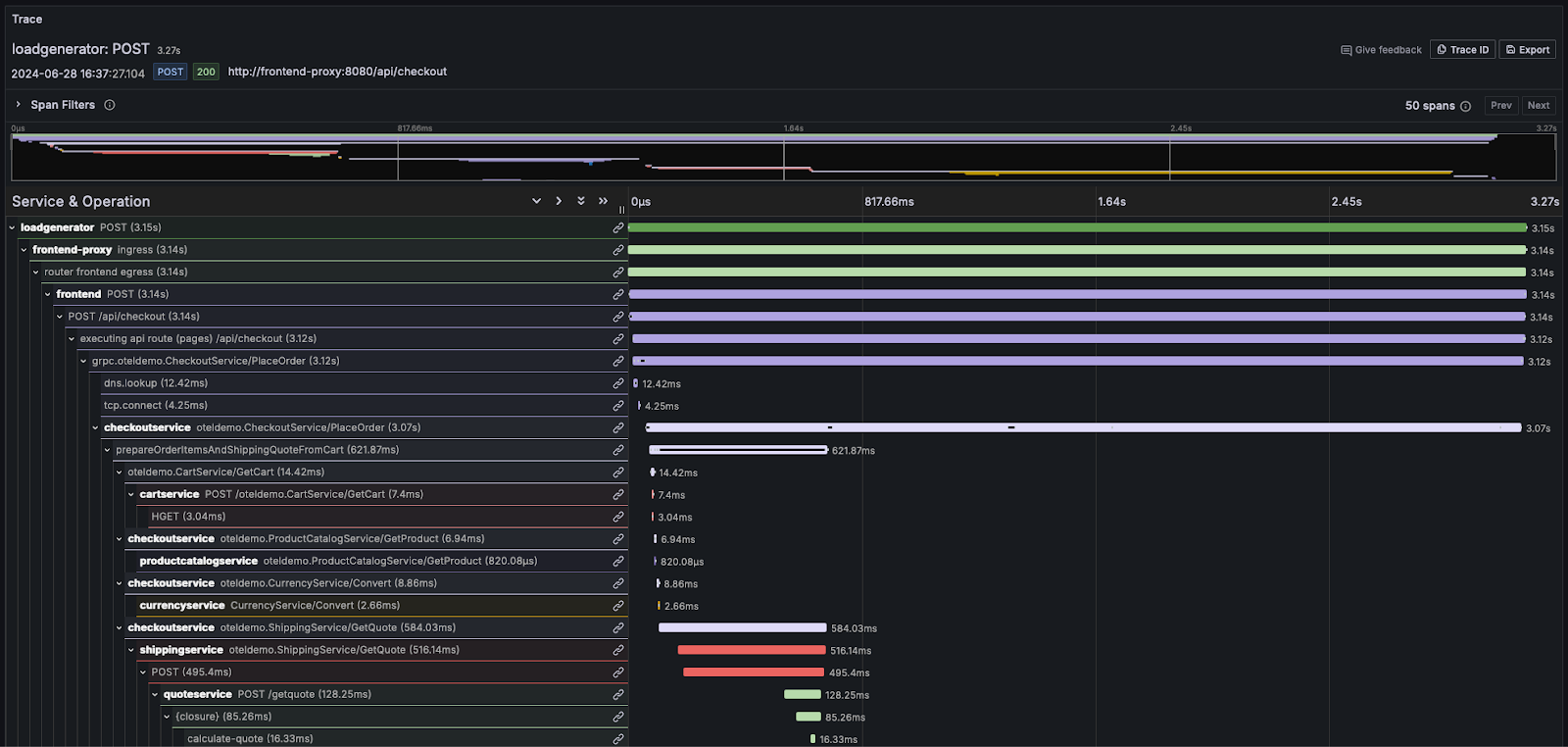
For users needing to familiarize themselves deeply with the concepts of logs and traces, we highly recommend the OpenTelemetry documentation.