
This blog post is part of the Supercharging your large ClickHouse data loads series:
Introduction
ClickHouse is designed to be fast and resource-efficient. If you let it, ClickHouse can utilize the hardware it runs on up to the theoretical limits and load data blazingly fast. Or you can reduce the resource usage of large data loads. Depending on what you want to achieve. In this three-part blog series, we will provide the necessary knowledge plus guidance, and best practices to achieve both resiliency and speed for your large data loads. This first part lays the foundation by describing the basic data insert mechanics in ClickHouse and its three main factors for controlling resource usage and performance. In a second post, we will go on a race track and tune the speed of a large data load to the max. In the final closing part of this series, we will discuss measures for making your large data loads robust and resilient against transient issues like network interruptions.
Let's start with exploring the basic ClickHouse data insert mechanics.
Data insert mechanics
The following diagram sketches the general mechanics of a data insert into a ClickHouse table of the MergeTree engine family:
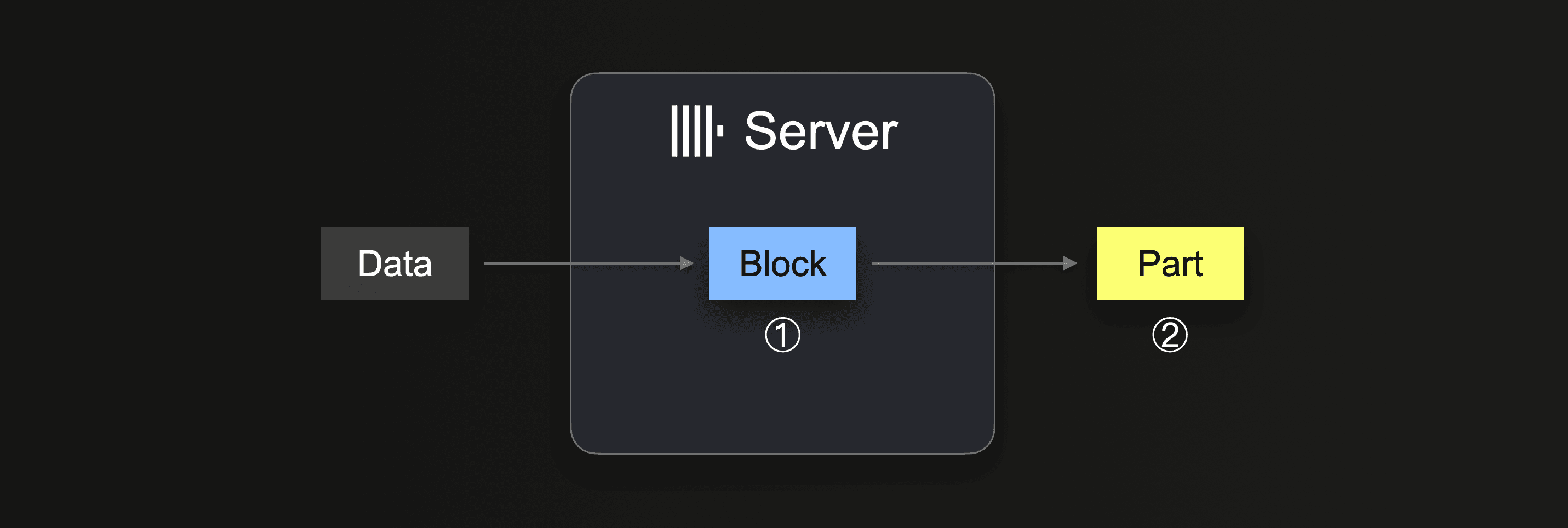 The server receives some data portion (e.g., from an insert query), and ① forms (at least) one in-memory insert block (per partitioning key) from the received data. The block’s data is sorted, and table engine-specific optimizations are applied. Then the data is compressed and ② written to the database storage in the form of a new data part.
The server receives some data portion (e.g., from an insert query), and ① forms (at least) one in-memory insert block (per partitioning key) from the received data. The block’s data is sorted, and table engine-specific optimizations are applied. Then the data is compressed and ② written to the database storage in the form of a new data part.
Note that there are also cases where the client forms the insert blocks instead of the server.
Three main factors influence the performance and resource usage of ClickHouse’s data insert mechanics: Insert block size, Insert parallelism and Hardware size. We will discuss these factors and the ways to configure them in the remainder of this post.
Insert block size
Impact on performance and resource usage
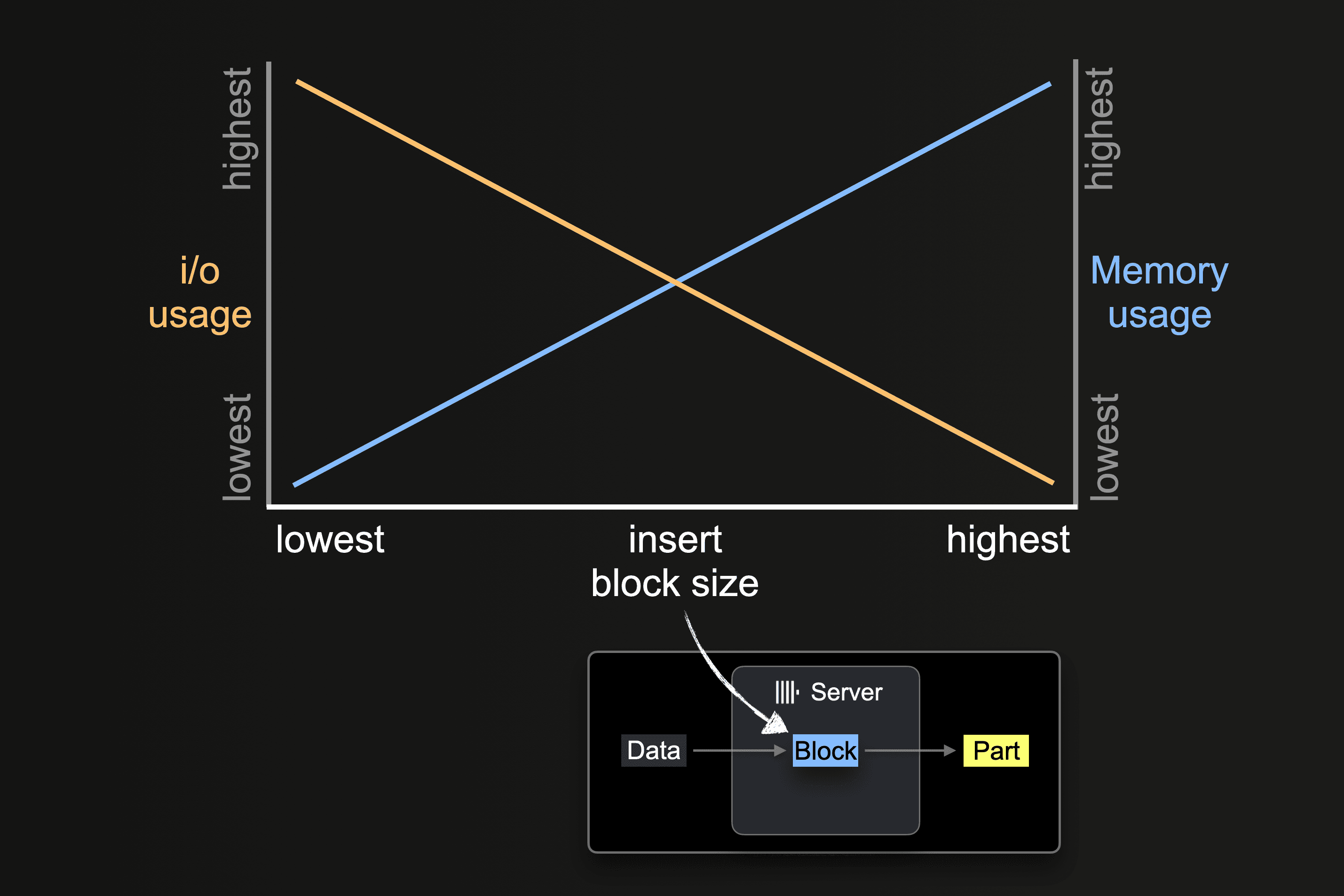 The insert block size impacts both the disk file i/o usage and memory usage of a ClickHouse server. Larger insert blocks use more memory but generate larger and fewer initial parts. The fewer parts ClickHouse needs to create for loading a large amount of data, the less disk file i/o and automatic background merges required.
The insert block size impacts both the disk file i/o usage and memory usage of a ClickHouse server. Larger insert blocks use more memory but generate larger and fewer initial parts. The fewer parts ClickHouse needs to create for loading a large amount of data, the less disk file i/o and automatic background merges required.
How the insert block size can be configured depends on how the data is ingested. Do the ClickHouse servers themselves pull it, or do external clients push it?
Configuration when data is pulled by ClickHouse servers
When using an INSERT INTO SELECT query in combination with an integration table engine, or a table function, the data is pulled by the ClickHouse server itself:
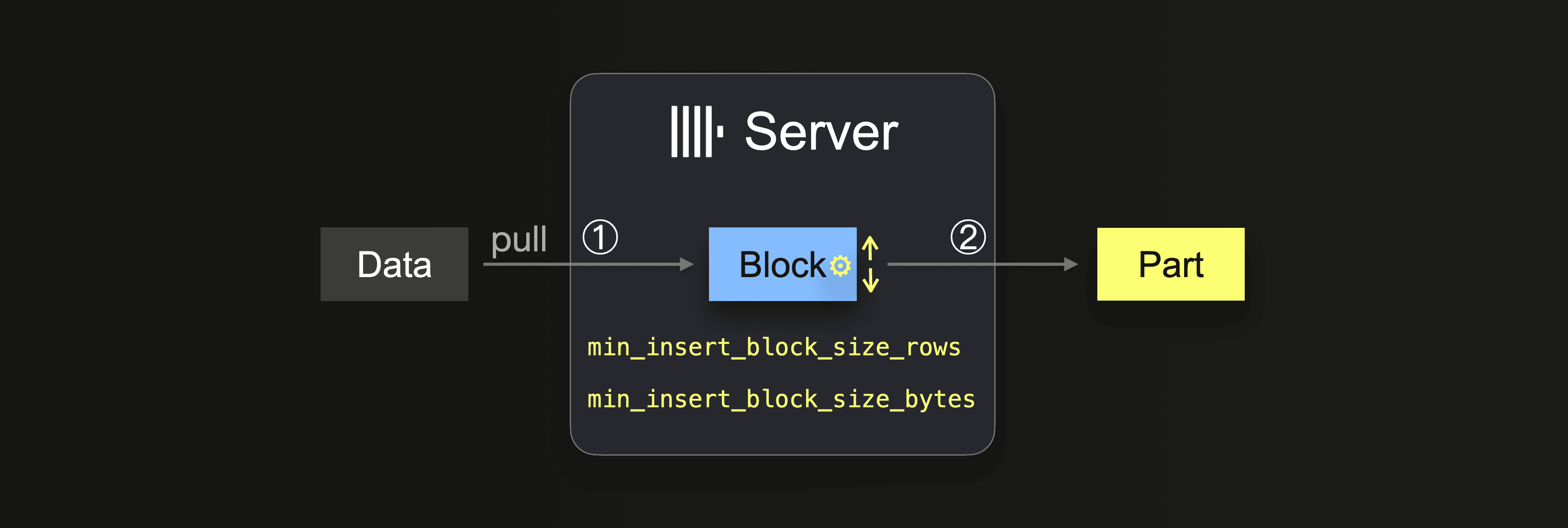 Until the data is completely loaded, the server executes a loop:
Until the data is completely loaded, the server executes a loop:
① Pull and parse the next portion of data and form an in-memory data block (one per partitioning key) from it.
② Write the block into a new part on storage.
Go to ①
In ① the portion size depends on the insert block size, which can be controlled with two settings:
- min_insert_block_size_rows (default: 1048545 million rows)
- min_insert_block_size_bytes (default: 256 MB)
When either the specified number of rows is collected in the insert block, or the configured amount of data is reached (whatever happens first), then this will trigger the block being written into a new part. The insert loop continues at step ①.
Note that the min_insert_block_size_bytes value denotes the uncompressed in-memory block size (and not the compressed on-disk part size). Also, note that the created blocks and parts rarely precisely contain the configured number of rows or bytes, as ClickHouse is streaming and processing data row-block-wise. Therefore these settings specify minimum thresholds.
Configuration when data is pushed by clients
Depending on the data transfer format and interface used by the client or client library, the in-memory data blocks are formed by either the ClickHouse server or the client itself. This determines where and how the block size can be controlled. This further also depends on if synchronous or asynchronous inserts are used.
Synchronous inserts
When the server forms the blocks
When a client grabs some data and sends it with a synchronous insert query in non-native format (e.g., the JDBC driver uses RowBinary for inserts), the server parses the insert query’s data and forms (at least) one in-memory block (per partitioning key) from it, which is written to storage in the form of a part:
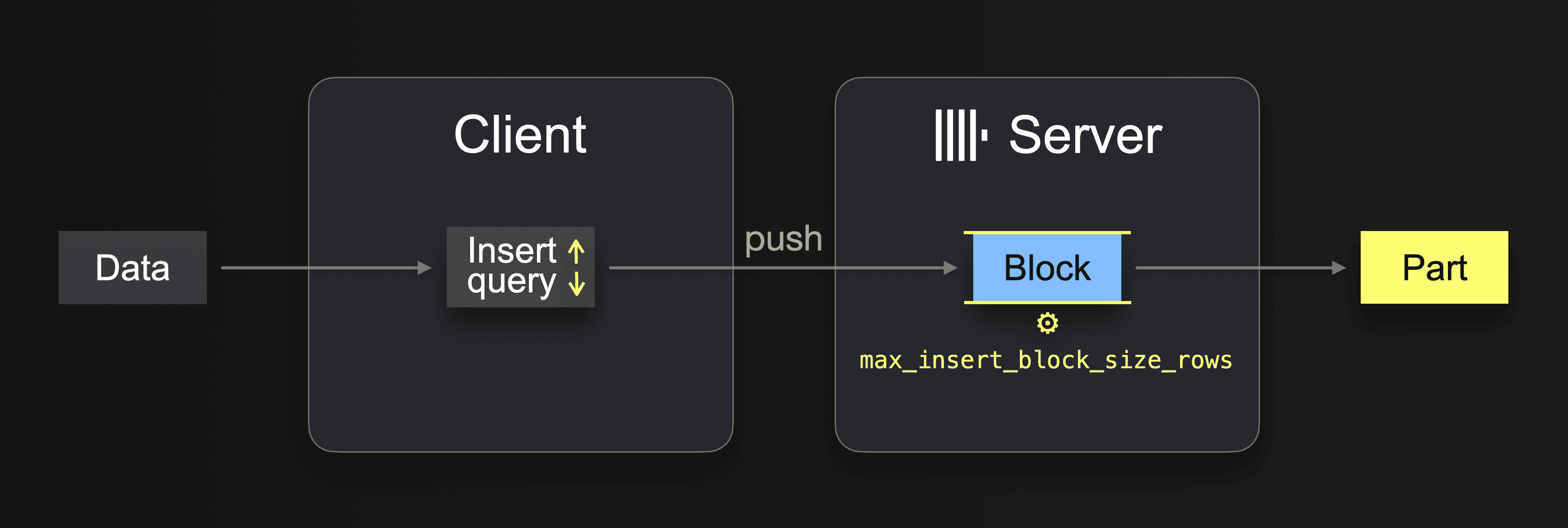 The insert query’s number of row values automatically controls the block size. However, the maximum size of a block (per partitioning key) can be configured with the max_insert_block_size rows setting. If a single block formed from the insert query’s data contains more than
The insert query’s number of row values automatically controls the block size. However, the maximum size of a block (per partitioning key) can be configured with the max_insert_block_size rows setting. If a single block formed from the insert query’s data contains more than max_insert_block_size rows (default value is ~ 1 million rows), then the server creates additional blocks and parts, respectively.
To minimize the number of created (and to-be-merged) parts, we generally recommend sending fewer but larger inserts instead of many small inserts by buffering data client-side and inserting data as batches.
When the client forms the blocks
The ClickHouse command-line client (clickhouse-client), and some of the programming language-specific libraries like the Go, Python, and C++ clients, form the insert blocks client side and send them in native format over the native interface to a ClickHouse server, which directly writes the block to storage.
For example, if the ClickHouse command-line client is used for inserting some data:
./clickhouse client --host ... --password … \
--input_format_parallel_parsing 0 \
--max_insert_block_size 2000000 \
--query "INSERT INTO t FORMAT CSV" < data.csv
Then the client by itself parses the data and forms in-memory blocks (per partitioning key) from the data and sends it in native format via the native ClickHouse protocol to the server, which writes the block to storage as a part:
 The client-side in-memory block size (in a count of rows) can be controlled via the
The client-side in-memory block size (in a count of rows) can be controlled via the max_insert_block_size (default: 1048545 million rows) command line option.
Note that we disabled parallel parsing in the example command-line call above. Otherwise, clickhouse-client will ignore the max_insert_block_size setting and instead squash several blocks resulting from parallel parsing into one insert block.
Also, note that the client-side max_insert_block_size setting is specific to clickhouse-client. You need to check the documentation and settings of your client library for similar settings.
Asynchronous data inserts
Alternatively, or in addition to client-side batching, you can use asynchronous inserts. With asynchronous data inserts, the blocks are always formed by the server regardless of which client, format, and protocol is used:
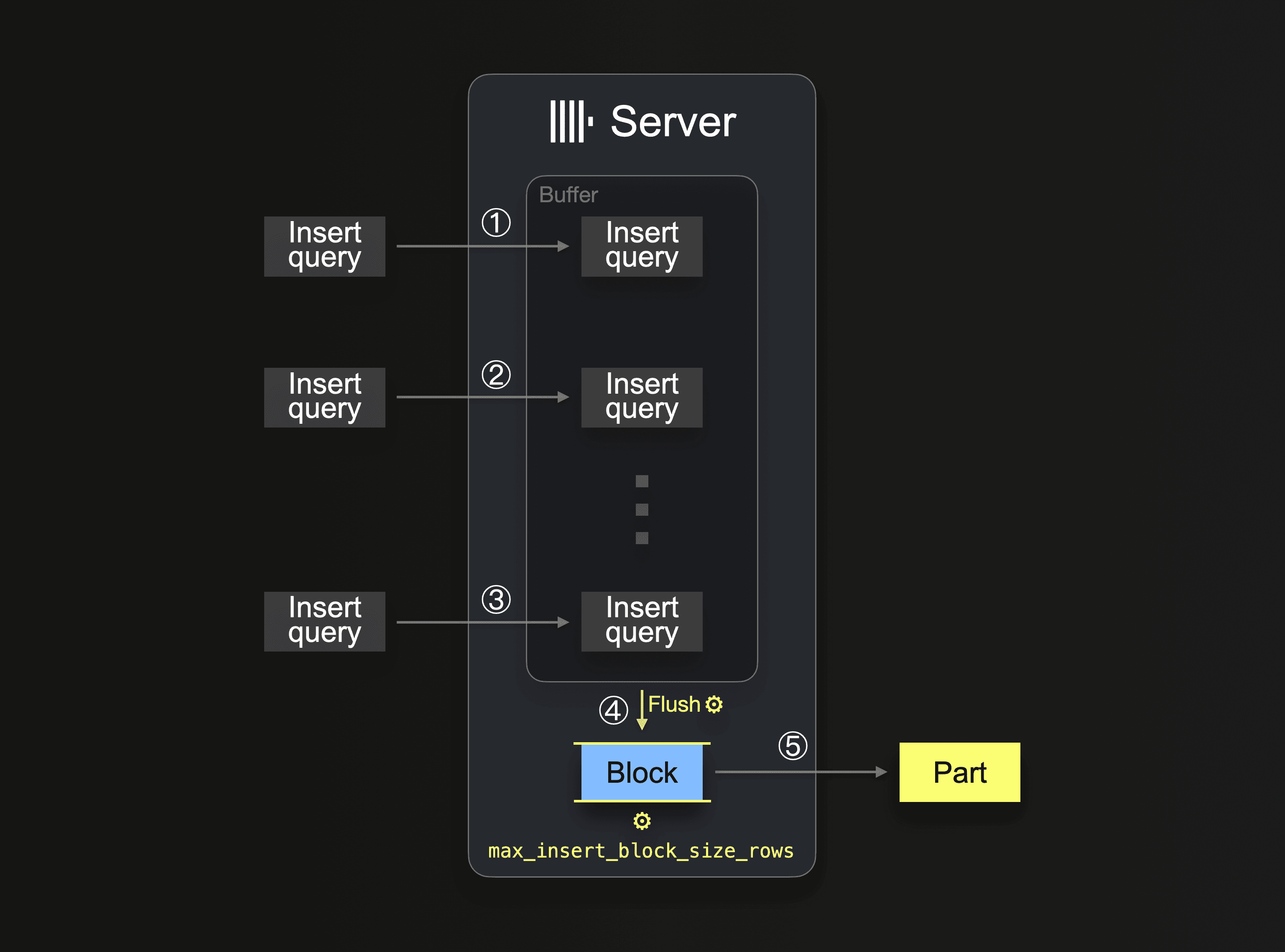 With asynchronous inserts, the data from received insert queries is first put into an in-memory buffer (see ①, ②, and ③ in the diagram above) and ④ when the buffer is flushed depending on configuration settings (e.g., once a specific amount of data is collected), the server parses the buffer’s data and forms an in-memory block (per partitioning key) from it, which is ⑤ written to storage in the form of a part. If a single block would contain more than
With asynchronous inserts, the data from received insert queries is first put into an in-memory buffer (see ①, ②, and ③ in the diagram above) and ④ when the buffer is flushed depending on configuration settings (e.g., once a specific amount of data is collected), the server parses the buffer’s data and forms an in-memory block (per partitioning key) from it, which is ⑤ written to storage in the form of a part. If a single block would contain more than max_insert_block_size rows, then the server creates additional blocks and parts, respectively.
More parts = more background part merges
The smaller the configured insert block size is, the more initial parts get created for a large data load, and the more background part merges are executed concurrently with the data ingestion. This can cause resource contention (CPU and memory) and require additional time (for reaching a healthy number of parts) after the ingestion is finished.
ClickHouse will continuously merge parts into larger parts until they reach a compressed size of ~150 GiB. This diagram shows how a ClickHouse server merges parts:
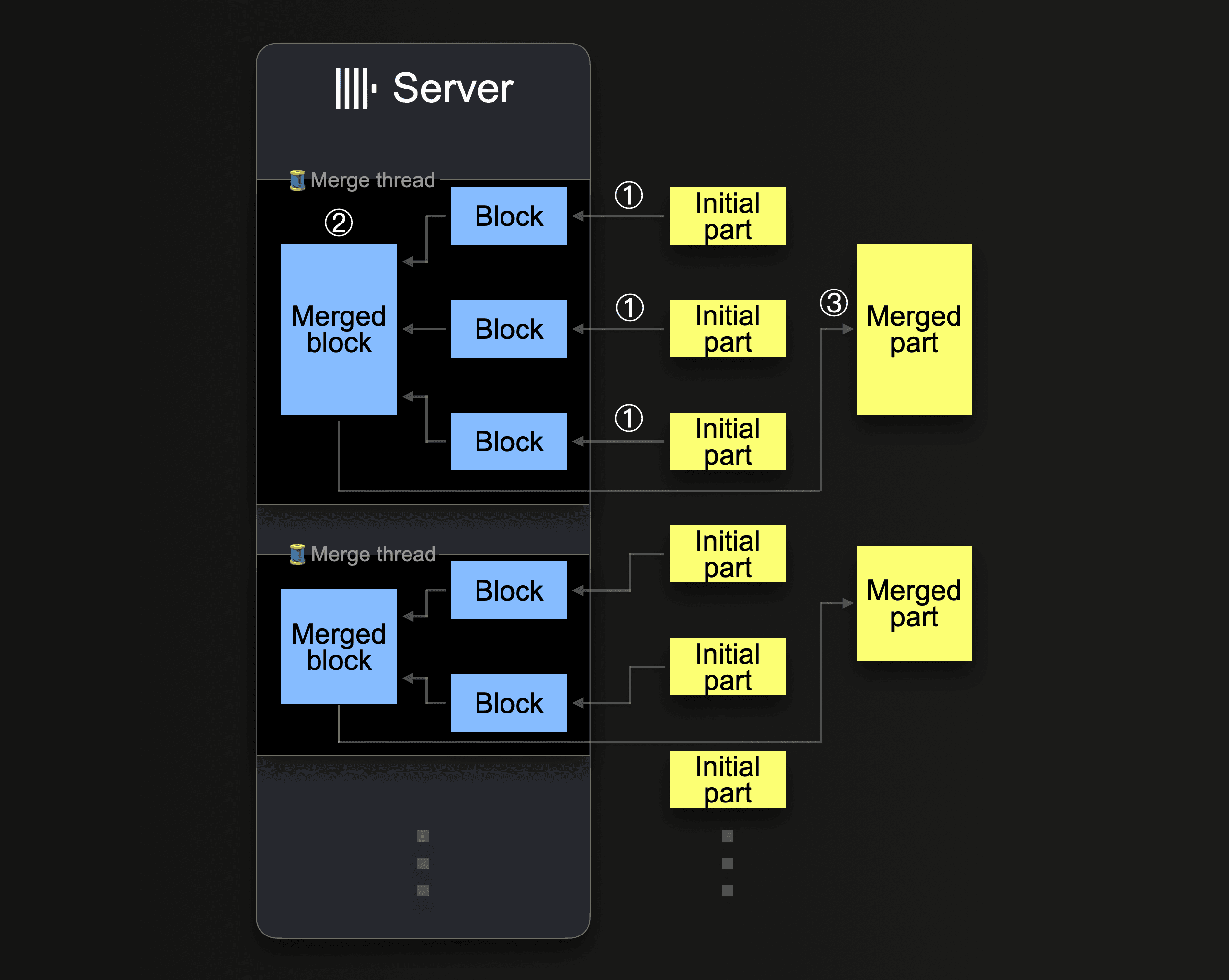 A single ClickHouse server utilizes several background merge threads to execute concurrent part merges. Each thread executes a loop:
A single ClickHouse server utilizes several background merge threads to execute concurrent part merges. Each thread executes a loop:
① Decide which parts to merge next, and load these parts as blocks into memory.
② Merge the loaded blocks in memory into a larger block.
③ Write the merged block into a new part on disk.
Go to ①
Note that ClickHouse is not necessarily loading the whole to-be-merged parts into memory at once. Based on several factors, to reduce memory consumption (for the sacrifice of merge speed), so-called vertical merging loads and merges parts by chunks of blocks instead of in one go. Further, note that increasing the number of CPU cores and the size of RAM increases the background merge throughput.
Parts that were merged into larger parts are marked as inactive and finally deleted after a configurable number of minutes. Over time, this creates a tree of merged parts. Hence the name merge tree table:
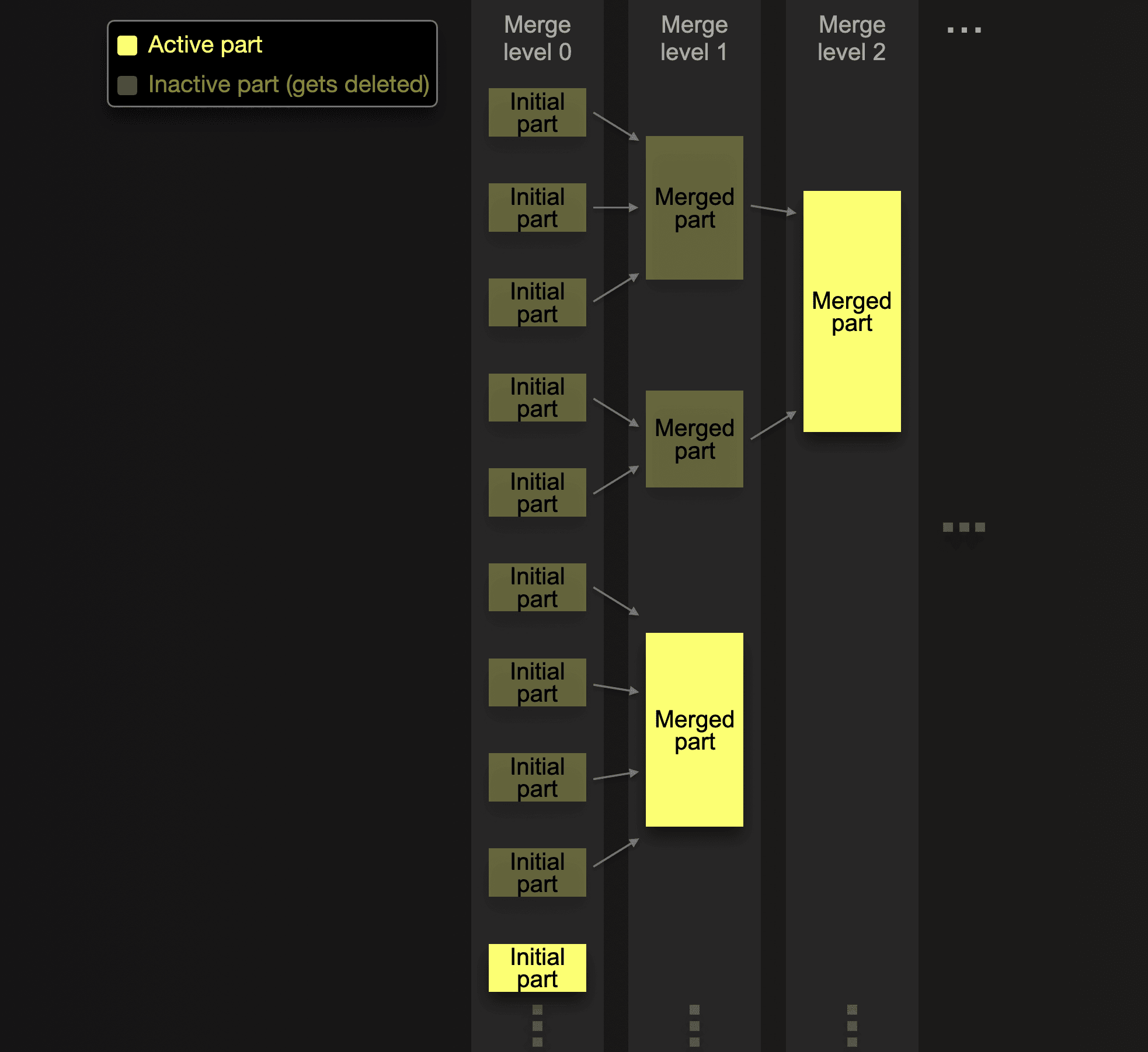 Each part belongs to a specific level indicating the number of merges leading to the part.
Each part belongs to a specific level indicating the number of merges leading to the part.
Insert parallelism
Impact on performance and resource usage
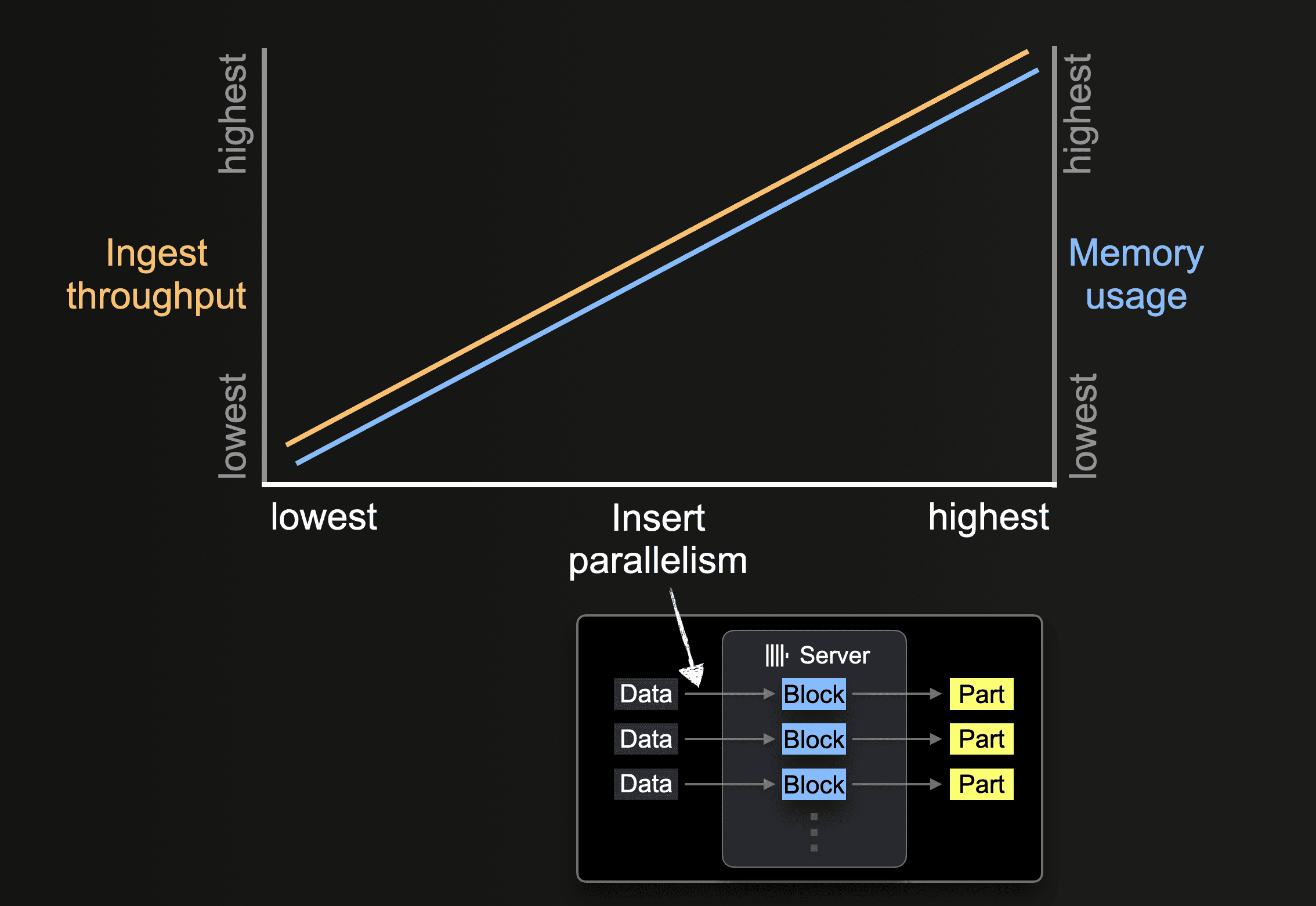 A ClickHouse server can process and insert data in parallel. The level of insert parallelism impacts the ingest throughput and memory usage of a ClickHouse server. Loading and processing data in parallel requires more main memory but increases the ingest throughput as data is processed faster.
A ClickHouse server can process and insert data in parallel. The level of insert parallelism impacts the ingest throughput and memory usage of a ClickHouse server. Loading and processing data in parallel requires more main memory but increases the ingest throughput as data is processed faster.
How the level of insert parallelism can be configured depends again on how the data is ingested.
Configuration when data is pulled by ClickHouse servers
Some integration table functions like s3, url, and hdfs allow specifying sets of to-be-loaded-file names via glob patterns. When a glob pattern matches multiple existing files, ClickHouse can parallelize reads across and within these files and insert the data in parallel into a table by utilizing parallel running insert threads (per server):
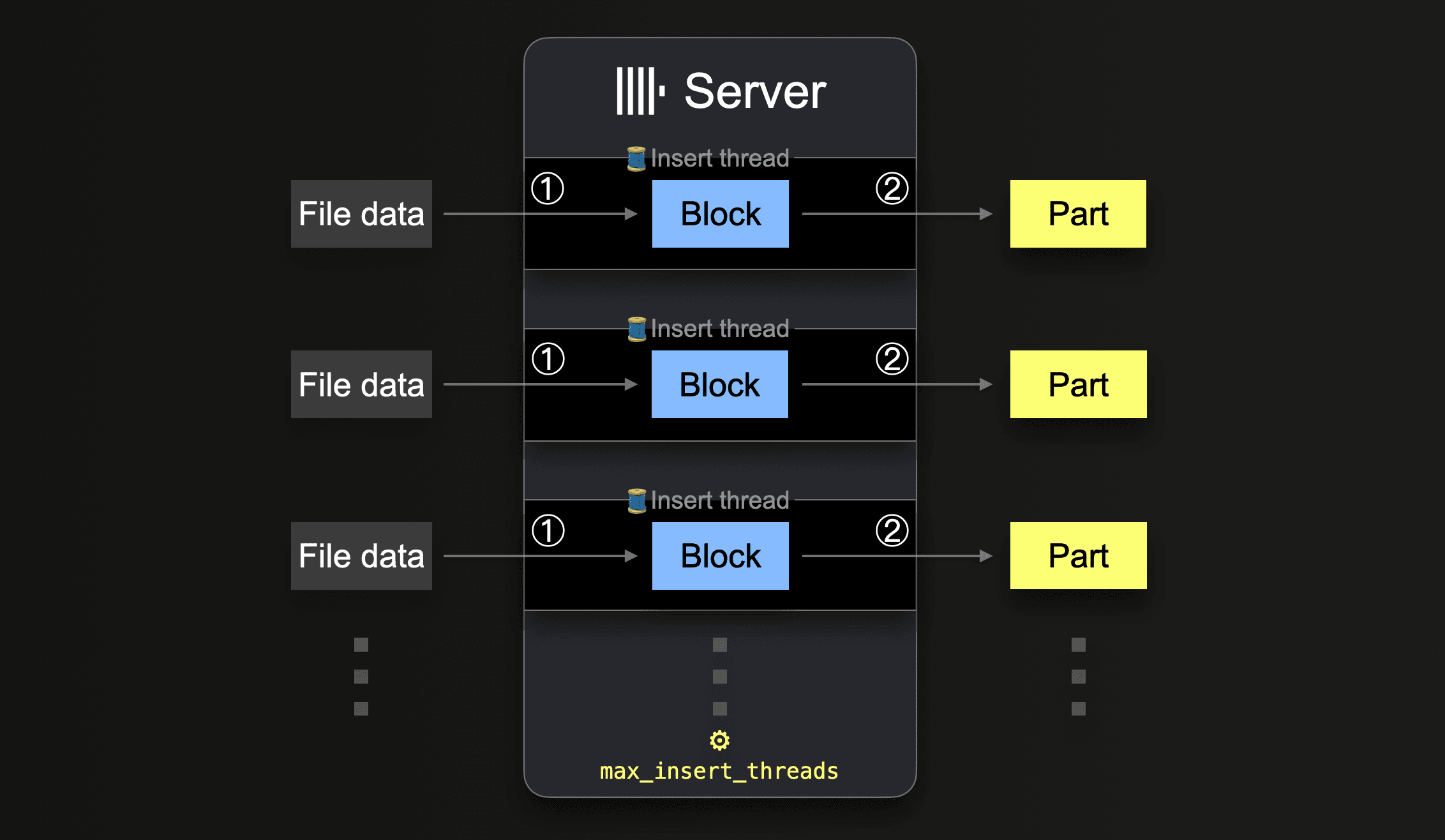 Until all data from all files is processed, each insert thread executes a loop:
Until all data from all files is processed, each insert thread executes a loop:
① Get the next portion of unprocessed file data (portion size is based on the configured block size) and create an in-memory data block from it.
② Write the block into a new part on storage.
Go to ①.
The number of such parallel insert threads can be configured with the max_insert_threads setting. The default value is 1 for OSS and 4 for ClickHouse Cloud.
With a large number of files, the parallel processing by multiple insert threads works well. It can fully saturate both the available CPU cores and the network bandwidth (for parallel file downloads). In scenarios where just a few large files will be loaded into a table, ClickHouse automatically establishes a high level of data processing parallelism and optimizes network bandwidth usage by spawning additional reader threads per insert thread for reading (downloading) more distinct ranges within large files in parallel. For the advanced reader, the settings max_download_threads and max_download_buffer_size may be of interest. This mechanism is currently implemented for the s3 and url table functions. Furthermore, for files that are too small for parallel reading, to increase throughput, ClickHouse automatically prefetches data by pre-reading such files asynchronously.
Parallel servers
Some of the integration table functions featuring glob patterns for loading multiple files in parallel also exist in a cluster version, e.g., s3Cluster, hdfsCluster, and urlCluster. These table functions increase the level of insert parallelism further by utilizing the aforementioned multiple parallel insert threads on multiple servers in parallel:
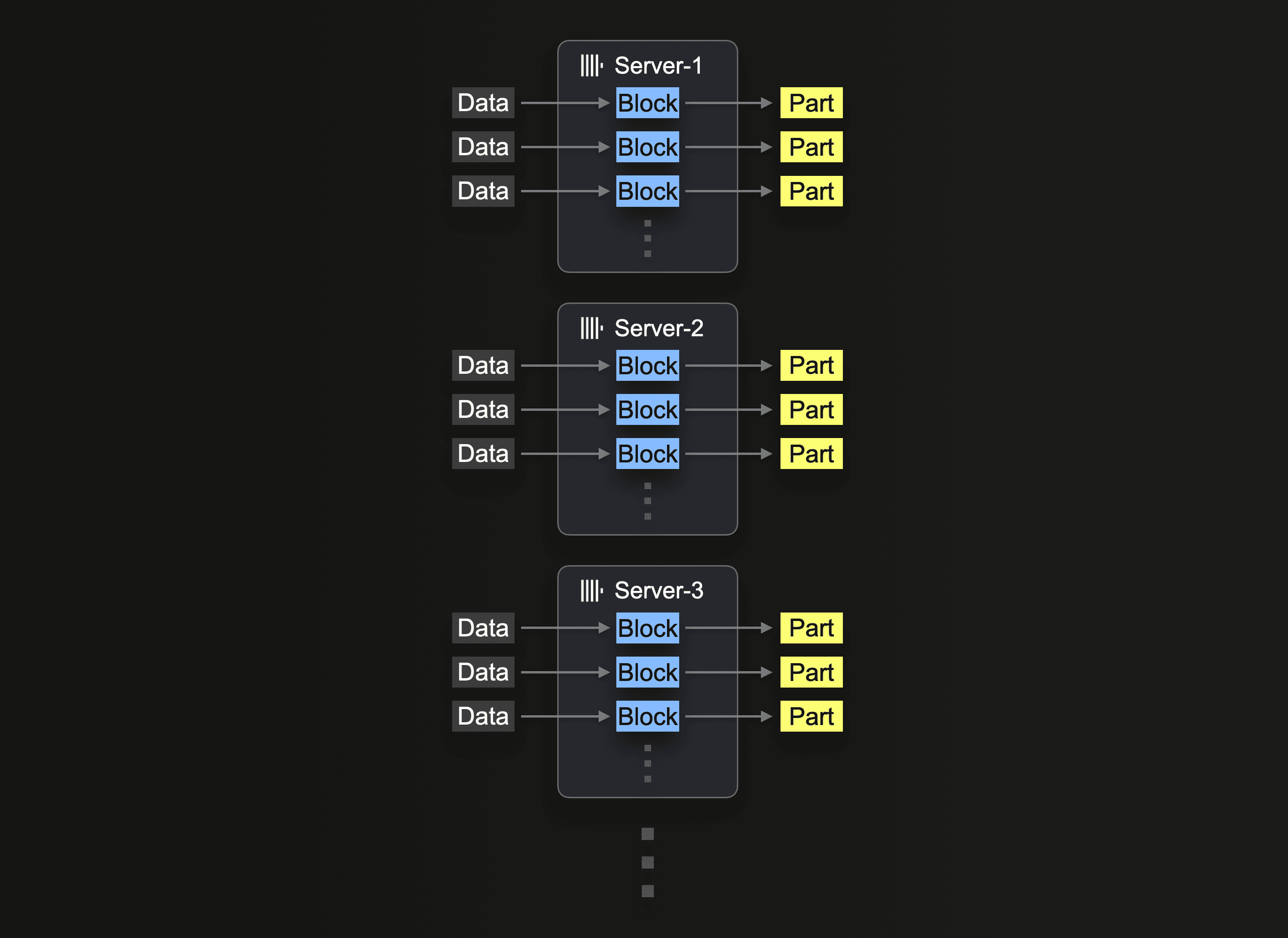 The server that initially receives the insert query first resolves the glob pattern and then dispatches the processing of each matching file dynamically to the other servers (and himself).
The server that initially receives the insert query first resolves the glob pattern and then dispatches the processing of each matching file dynamically to the other servers (and himself).
Configuration when data is pushed by clients
A ClickHouse server can receive and execute insert queries concurrently. A client can utilize this by running parallel client-side threads:
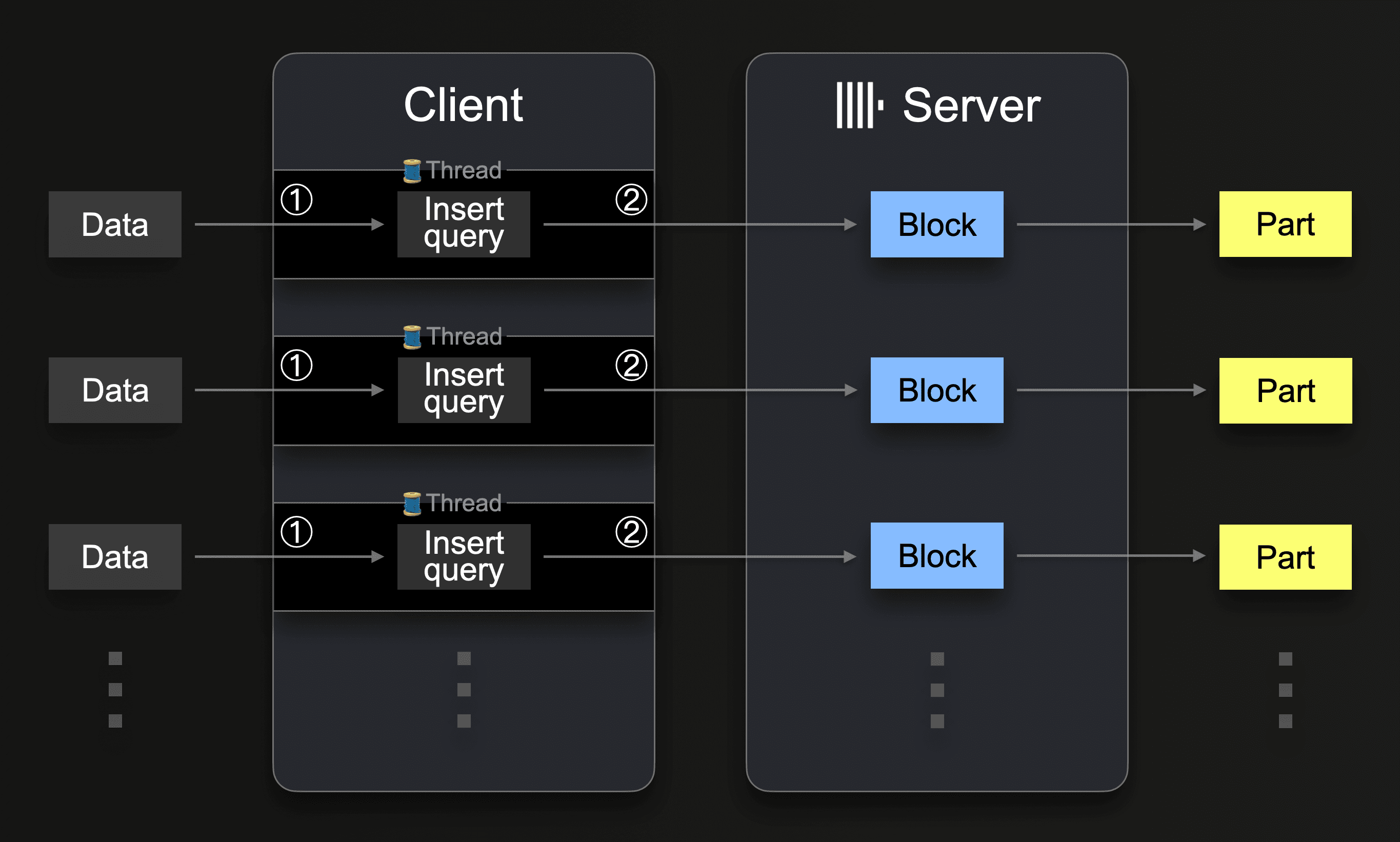 Each thread executes a loop:
Each thread executes a loop:
① Get the next data portion and create an insert from it.
② Send the insert to ClickHouse (and wait for the acknowledgment that the insert succeeded).
Go to ①
Alternatively, or in addition, multiple clients can send data in parallel to ClickHouse:
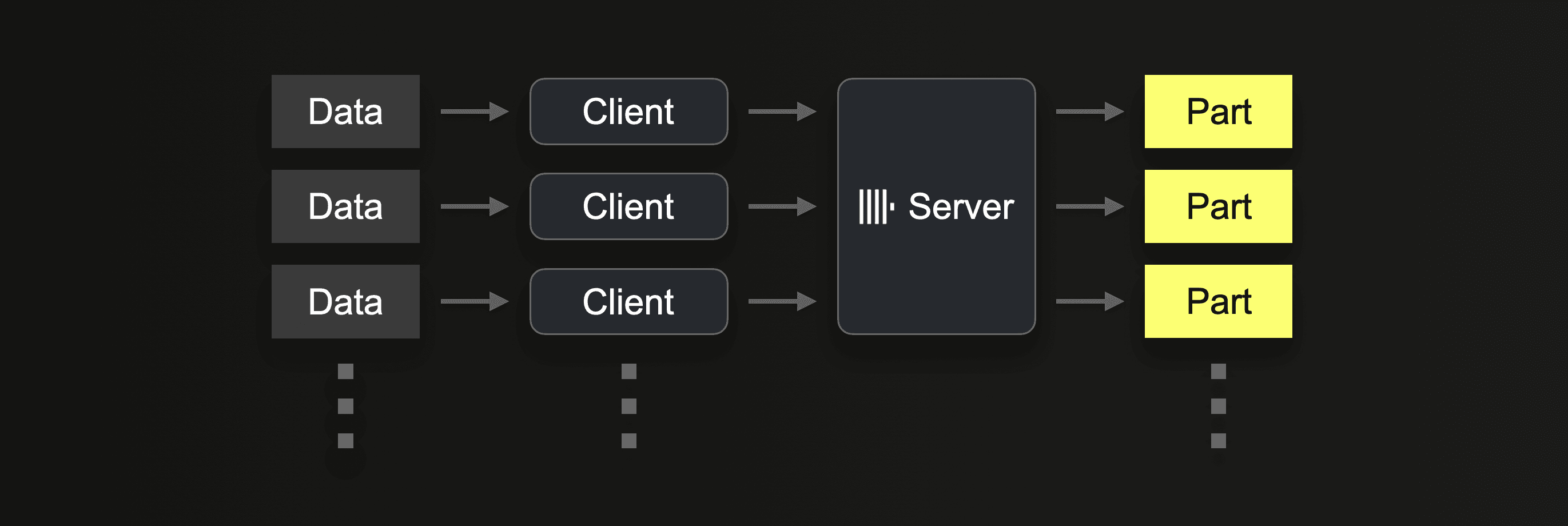
Parallel servers
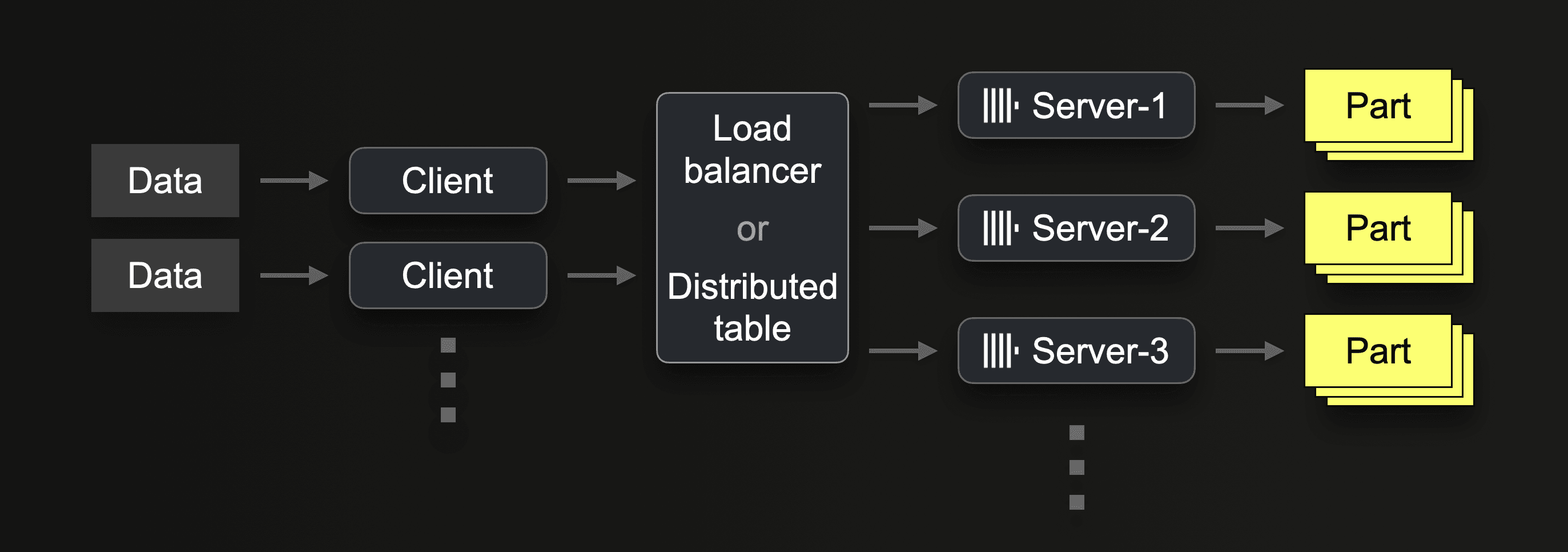
In ClickHouse Cloud, inserts are evenly distributed over multiple ClickHouse servers with a load balancer. Traditional shared-nothing ClickHouse clusters can use a combination of sharding and a distributed table for load balancing inserts over multiple servers:
Hardware size
Impact on performance
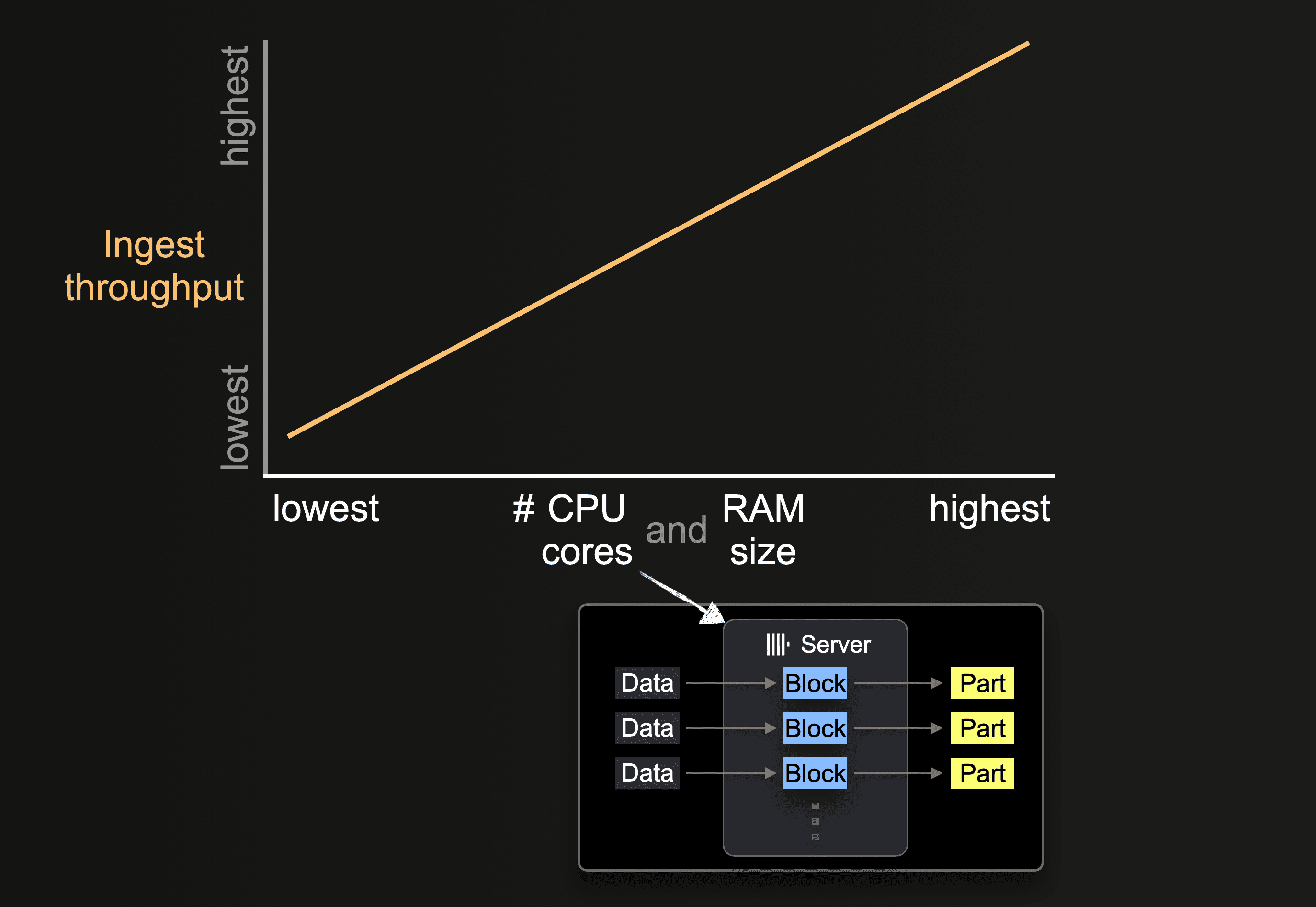 The number of available CPU cores and the size of RAM impacts the
The number of available CPU cores and the size of RAM impacts the
- supported initial size of parts
- possible level of insert parallelism
- throughput of background part merges
and, therefore, the overall ingest throughput.
How easily the number of CPU cores and the size RAM can be changed depends on whether the ingestion occurs in ClickHouse Cloud or a traditional shared-nothing ClickHouse cluster.
ClickHouse Cloud
Because storage is completely separated from the ClickHouse servers in ClickHouse Cloud, you can freely either change the size (CPU and RAM) of existing servers or add additional servers quickly (without requiring any physical resharding or rebalancing of the data):
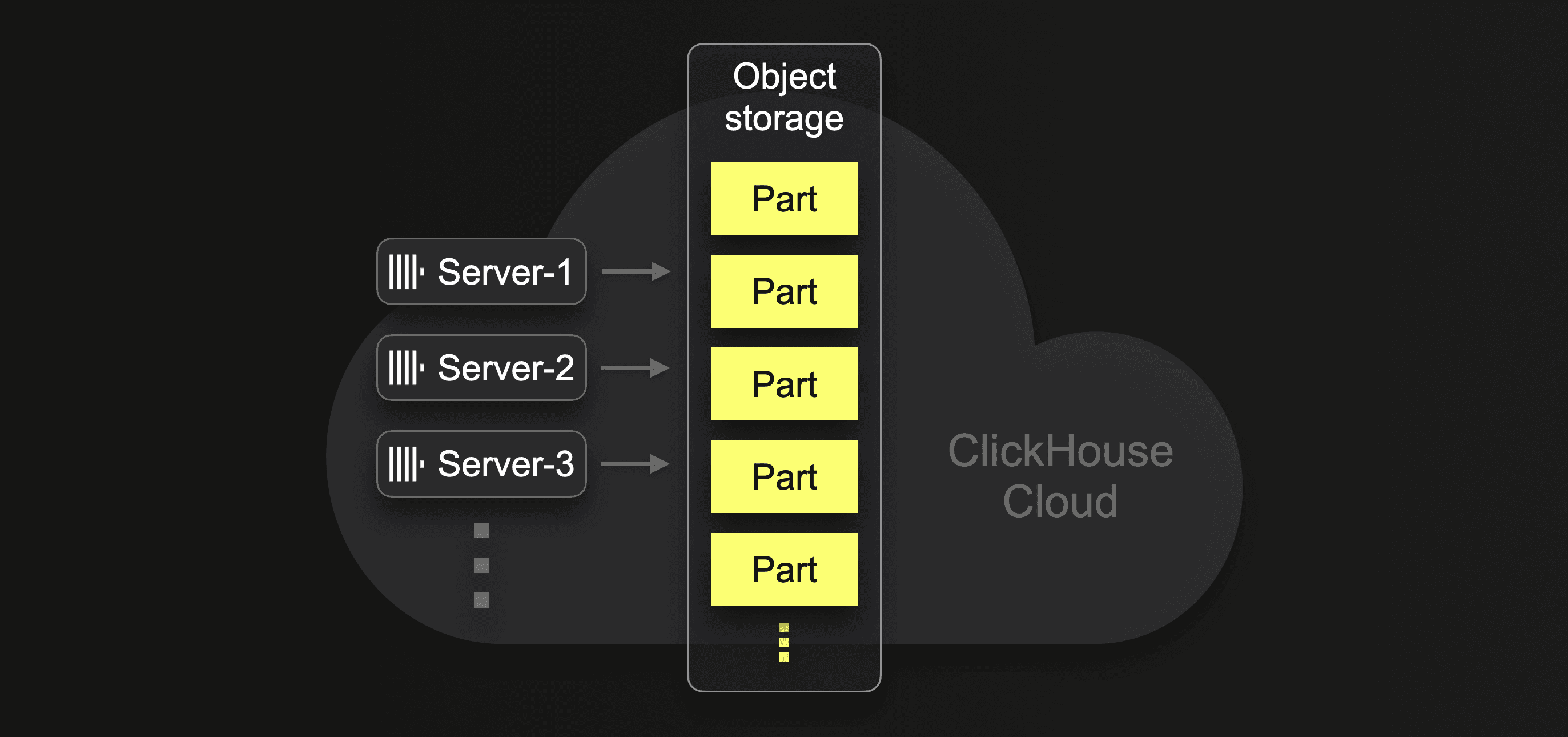 Additional servers will then automatically participate in parallel data ingestion and background part merges, which can drastically reduce the overall ingestion time.
Additional servers will then automatically participate in parallel data ingestion and background part merges, which can drastically reduce the overall ingestion time.
Traditional shared-nothing ClickHouse cluster
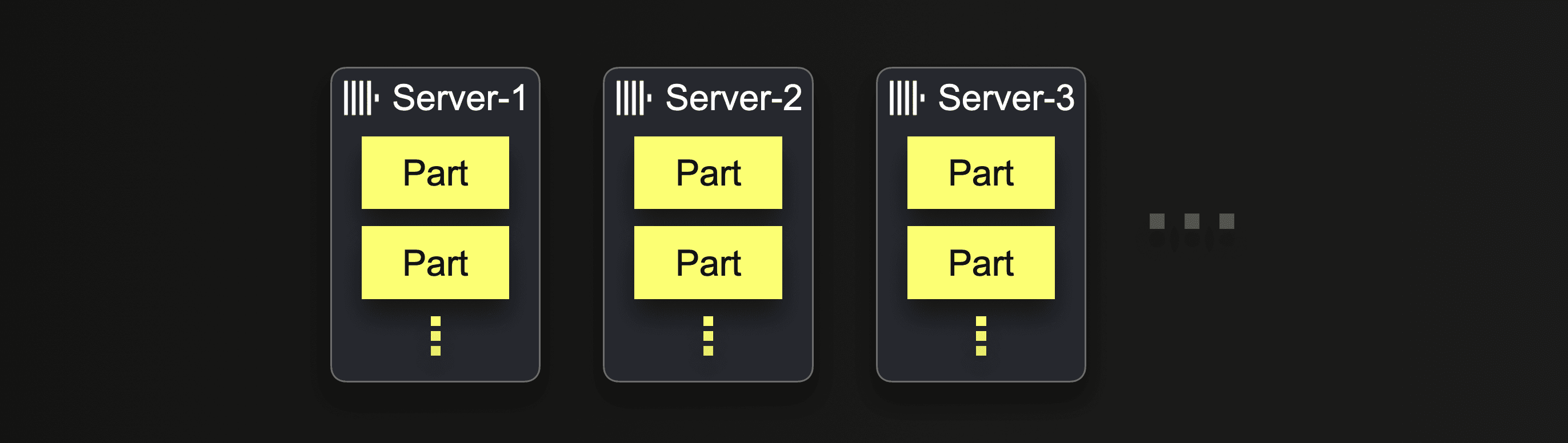
In a traditional shared-nothing ClickHouse cluster, data is stored locally on each server:
 Adding additional servers requires manual configuration changes and more time than in ClickHouse Cloud.
Adding additional servers requires manual configuration changes and more time than in ClickHouse Cloud.
Summary
You can let ClickHouse load data blazingly fast by allowing its data insert mechanics to fully utilize the hardware it runs on. Alternatively, you can reduce the resource usage of large data loads. Depending on what your data load scenario is. For this, we have explored how the data insert mechanics of ClickHouse work and how you can control and configure the three main performance and resource usage factors for large data loads in ClickHouse: Insert block size, Insert parallelism, and Hardware size.
With that, we set the scene for our two follow-up posts turning this knowledge into best practices for fast and resilient large data loads. In the next post of this series, we are going on a race track and making a large data insert 3 times faster than with default settings. On the same hardware.
Stay tuned!


